%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
sequenceDiagram
participant User
participant Input
participant Reactive
participant API
participant Output
User->>Input: Adjusts bill length slider
Input->>Reactive: Value changes
Note over Reactive: vals()<br>recalculates
User->>Input: Clicks "Predict" button
Input->>Reactive: predict event triggered
Reactive->>API: POST request with data
API->>Reactive: Returns prediction
Reactive->>Output: Updates display
Output->>User: Shows predicted mass
Python App Logging
In this lab, I’ll be updating the Shiny for Python application from lab 3 with logging and performance metrics. As a refresher, I’ve created a diagram below that illustrates the app user inputs, reactives, and the API request/response.
You can access the code for this application in this folder on GitHub.
Packages
In the top of our app-log.py file, we load the following packages.
from shiny import App, render, ui, reactive
import requests
import json
import logging
import time
import os
from datetime import datetime
from pathlib import PathConfigure logging
Below we configure the logging in the application with logging.1 Path("logs") creates a pathlib.Path object, which is our log directory (log_dir). The log_file is created by joining paths with /, which automatically handles path separators for different operating systems.
def setup_logging():
"""Configure logging with file and console output"""
log_dir = Path("logs")
log_dir.mkdir(exist_ok=True)
log_file = log_dir / "shiny_app.log"
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(log_file, mode='a'),
logging.StreamHandler()
]
)
return str(log_file)
log_file_path = setup_logging()
logging.info("Shiny for Python application initialized")- 1
-
creates a
pathlib.Pathobject, which is more powerful than a string. - 2
- creates directory if it doesn’t exist (won’t raise an error if directory already exists)
- 3
-
Joins paths using
/operator (equivalent toos.path.join(log_dir, "filename"))
- 4
-
Configuration for log level, file format, and handlers.
- 5
-
Only
INFO,WARNING,ERROR, andCRITICALmessages are logged).
- 6
-
Every log entry has the same format (
timestamp-level-message) - 7
-
Logs accumulate across application restarts
- 8
-
Convert
Pathobject to string
- 9
-
Store the path (kater used for file monitoring)
- 10
-
Log app initialization with
logging.info()
logging.basicConfig() “does basic configuration for the logging system.” We specify the level, format, and handlers.
level:logging.INFOis the “root logger level.” This meansDEBUGmessages are ignored.format: “Defaults to attributeslevelname,nameandmessageseparated by colons.”
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph LR
LogMessage(["<strong>Log<br>created</strong>"]) --> Logger("Python<br>logger")
Logger --> FileHandler("<strong>logging.FileHandler</strong>")
Logger --> ConsoleHandler("<strong>logging.StreamHandler</strong>")
subgraph FH["FileHandler"]
FH1("mode='a'<br>(append mode)")
FH2("Creates file if<br>doesn't exist")
FH3("<strong>Writes to:<br><code>logs/shiny_app.log</code></strong>")
end
FileHandler -.-> FH1 & FH2 & FH3
subgraph SH["StreamHandler"]
SH1("Default: sys.stderr")
SH2("<strong>Outputs to<br>console/terminal</strong>")
SH3("Real-time display")
end
ConsoleHandler -.-> SH1 & SH2 & SH3
style LogMessage fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style Logger fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style FileHandler fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style ConsoleHandler fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style FH1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style FH2 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style FH3 fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style SH1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style SH2 fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style SH3 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style FH fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
style SH fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
handlers: these are ‘an iterable of already created handlers to add to the root logger.’
FileHandler()“sends logging output to a disk file. It inherits the output functionality fromStreamHandler.”mode='a'means previous log entries are preserved
StreamHandler()“sends logging output to streams such assys.stdout,sys.stderror any file-like object (or, more precisely, any object which supportswrite()andflush()methods).”
This results in the following log in the Console:
2025-09-15 06:58:53,346 - INFO - New session started - Session: py_79024And our log file is created in logs/ directory:
├── app-log.py
├── logs
│ └── shiny_app.log
├── Python.Rproj
├── README.md
└── requirements.txt
2 directories, 5 files- 1
- New log file!
API configuration
Below we define the URLs for the API and ping (for the health check).
api_url = 'http://127.0.0.1:8080/predict'
ping_url = 'http://127.0.0.1:8080/ping'Session token
At the top of our application we’re going to create a ui.div() for displaying the session id.2
UI
Inside the ui.div(), we’ll add some custom CSS styling so the Session has persistent visibility (i.e., the element stays visible when the user is scrolling). The following CSS variables are used to style session ID output:
ui.div(
ui.strong("Session: "),
ui.output_text("session_display"),
style="position: fixed; top: 10px; right: 10px; z-index: 1000; color: #333; background: #fff; padding: 5px; border-radius: 3px; box-shadow: 0 2px 4px rgba(0,0,0,0.1);"
)- 1
-
Session ID output
- 2
- CSS styling for session ID
The ui.output_text() contains an id for the session_display.
Server
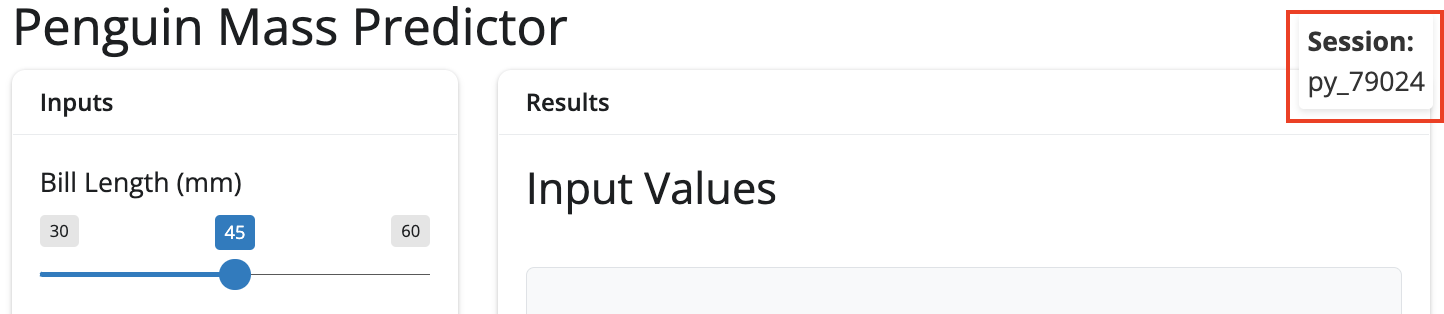
In the server, we start by creating the session_id object with f-string formatting (f"py_{result}"). This prepends py_ to the output (i.e., py_result).3 The py_ prefix is like as a namespace identifier so it’s clear these are Python-generated session IDs (not R, JavaScript, etc.), and provides a consistent format for parsing/filtering logs later.
def server(input, output, session):
session_id = f"py_{int(time.time() * 1000) % 100000}"
logging.info(f"New session started - Session: {session_id}")- 1
-
Shiny server definition
- 2
-
f-string for time
- 3
- f-string for session ID
The first log (logging.info) tells us the Shiny session has started.
2025-09-14 21:29:39,024 - INFO - New session started - Session: py_79024To render the session_id, we define session_display() under the @render.text decorator and link this to the id we created in the ui.output_text().
@render.text
def session_display():
return session_id[:8]- 1
-
Render decorator for session ID display
- 2
-
Definition of
session_display()function
- 3
-
Index the first 8 characters in
session_id
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph TB
Decorator("<strong>@render.text</strong>") --"<em>defines</em>"--> Function("session_display()")
Function --> Registration{{"Registers with Shiny's<br>reactive system"}}
Registration --"<em>binds to</em>"--> UIBinding("ui.output_text('session_display')")
UIBinding --> AutoUpdate("<strong>Automatically updates<br>UI when called</strong>")
style Decorator fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style Function fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style Registration fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff,text-align:center
style UIBinding fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style AutoUpdate fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
Params and Predictions
The model parameter inputs (penguin bill length, sex, and species) are described below. The inputs are passed to the API when the Predict button is clicked, and a model prediction is returned. The UI for this section of the application hasn’t changed much from the previous lab, but I’ve included a section for logging and monitoring.
UI
The diagram below attempts to capture the hierarchy of the UI functions:
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph TD
subgraph UIH["UI Hierarchy"]
Card("ui.card(<strong>'Results'</strong>) container")
Header("ui.card_header(<strong>'Results'</strong>)")
end
subgraph Inputs["Input Values"]
InputHeader("ui.h3(<strong>'Input Values'</strong>)")
subgraph iDiv["<strong>ui.div()</strong>"]
InpValOut("ui.output('<strong>vals_out</strong>')")
end
end
subgraph Preds["Predictions"]
PredHeader("ui.h3(<strong>'Predicted Mass'</strong>)")
subgraph pDiv["<strong>ui.div()</strong>"]
PredOut("ui.output_text('<strong>pred_out</strong>')")
end
end
Card --> Header
Header --> Inputs
Header --> Preds
PredHeader --"<em>Styled container</em>" --> pDiv
InputHeader --"<em>Styled container</em>" --> iDiv
style Card fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style Header fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style InputHeader fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style InpValOut fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style PredHeader fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style PredOut fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style UIH fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style Inputs fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style iDiv fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style Preds fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
style pDiv fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
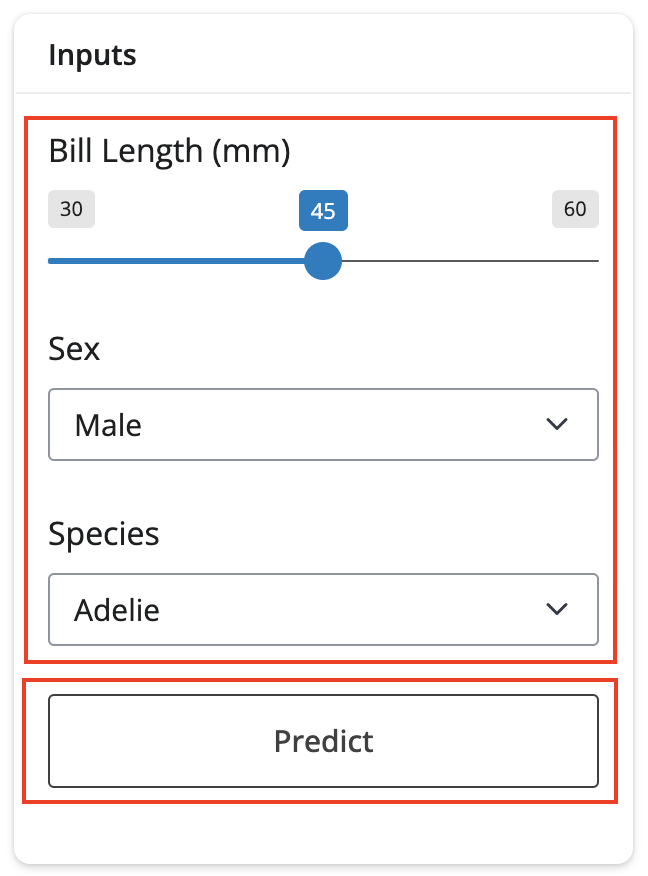
The input values are stored in a ui.card() and include our four reactives: input.bill_length(), input.sex(). input.species(), and input.predict().
ui.layout_columns(
ui.card(
ui.card_header("Inputs"),
ui.input_slider(id="bill_length", label="Bill Length (mm)", min=30, max=60, value=45, step=0.1),
ui.input_select(id="sex", label="Sex", choices=["Male", "Female"]),
ui.input_select(id="species", label="Species", choices=["Adelie", "Chinstrap", "Gentoo"]),
ui.input_action_button(id="predict", label="Predict")
),
# ...- 1
-
Numeric input for penguin bill length (mm)
- 2
-
Drop-down inputs for penguin sex and species
- 3
- Make a prediction (send request to API)
Instead of using the sidebar layout, I’ve place a second ui.card() inside the ui.layout_columns() and titled it Results. This includes the Input Values and Predicted Mass sections.
We can set the widths for each ui.card() with col_widths=[4, 8], which will give the general appearance of a sidebar (while leaving us with more screen real-estate for the System Status section we’ll add below).
The following CSS styling variables are used to give the input values display a console-like appearance:
font-family
font-size
background-color
padding
border-radius
max-height
overflow-y
border
white-space
The returned prediction is styled with the following CSS variables:
ui.layout_columns(
# ... <Inputs section omitted> ...
ui.card(
ui.card_header("Results"),
ui.h3("Input Values"),
ui.div(
ui.output_text("vals_out"),
style="font-family: 'Monaco', 'Courier New', monospace; font-size: 14px; background-color: #f8f9fa; padding: 10px; border-radius: 5px; max-height: 250px; overflow-y: auto; border: 1px solid #dee2e6; white-space: pre-wrap;"
),
ui.h3("Predicted Mass"),
ui.div(
ui.output_text("pred_out"),
style="font-size: 24px; font-weight: bold; text-align: center; padding: 15px; color: #0066cc;"
)
),
col_widths=[4, 8]
)- 1
-
div()for values being sent to API
- 2
-
Text output for values (plain text)
- 3
-
CSS styling for API values (formatted like the console output)
- 4
-
div()for prediction value returned from the API
- 5
-
Text output for response from API
- 6
- CSS styling for API values (formatted to be large and colorful)
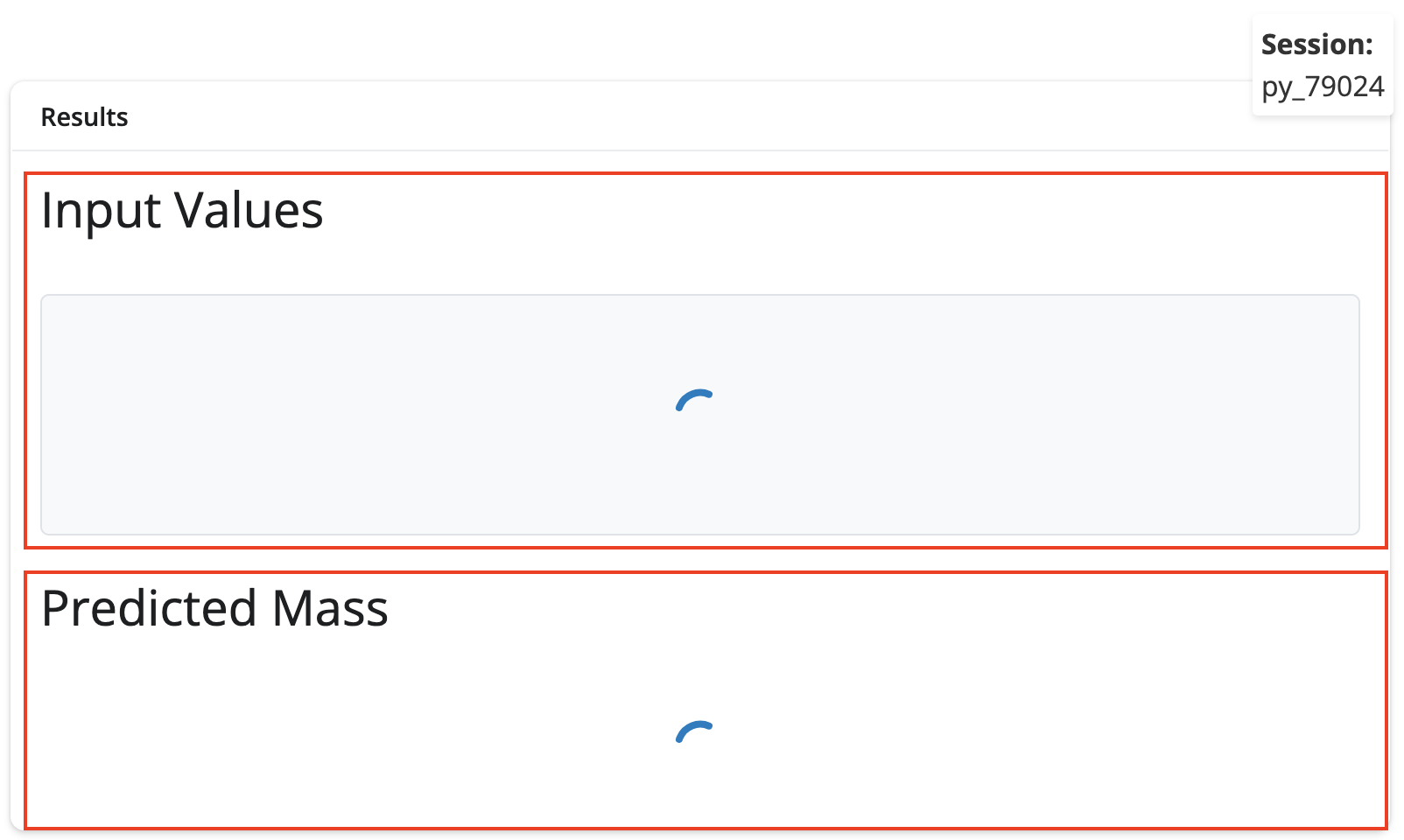
These outputs won’t render until we add the corresponding server components.
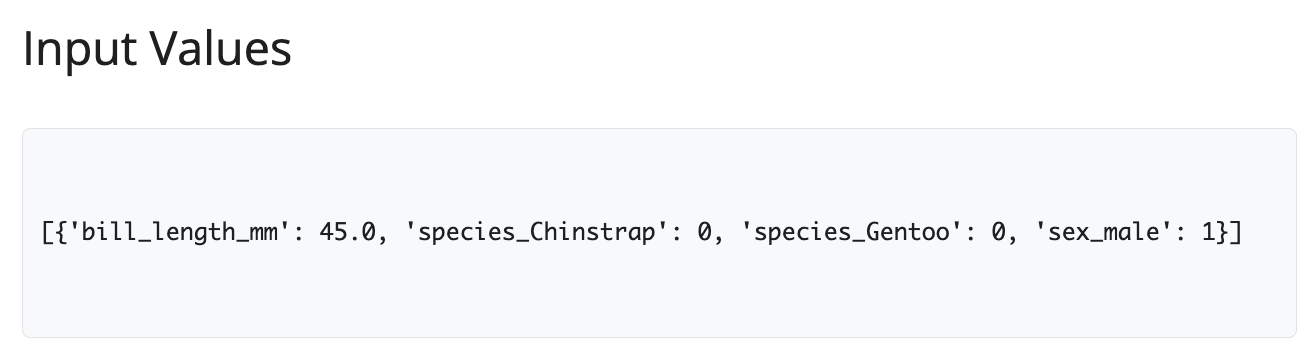
Input Values
I’ve separated the server code for the Input Values and Predicted Mass sections below. The user inputs are displayed as a plain-text representation of the values before they are sent to the API.
@reactive.calc
def vals():
bill_length = input.bill_length()
species = input.species()
sex = input.sex()
if bill_length < 30 or bill_length > 60:
logging.warning(f"Bill length out of typical range - Session: {session_id} - bill_length: {bill_length}")
d = [{
"bill_length_mm": float(bill_length),
"species_Chinstrap": int(species == "Chinstrap"),
"species_Gentoo": int(species == "Gentoo"),
"sex_male": int(sex == "Male")
}]
logging.debug(f"Input data prepared - Session: {session_id} - data: {json.dumps(d)}")
return d- 1
- Reactive inputs
- 2
-
Input validation with logging
- 3
-
Create data in LIST format (what API expects)
- 4
- Debug logging (with JSON formatted inputs)
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph LR
subgraph Inputs["Reactive Inputs"]
InputBillLength("<strong>input.bill_length()</strong>")
InputSex("<strong>input.sex()</strong>")
InputSpecies("<strong>input.species()</strong>")
end
Validation("Input Validation Logic")
APIFormat("API Format<br>Creation")
subgraph LogBeh["Logging Behaviors"]
ValidationLog("<strong>logging.warning for out-of-range</strong>")
DebugLog("<strong>logging.debug for data prep</strong>")
SessionLog("<strong>Session-specific logging</strong>")
end
InputBillLength --> Validation
InputSex & InputSpecies --"data<br>transformation"--> APIFormat
Validation --> ValidationLog
APIFormat --> DebugLog
style InputBillLength fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style InputSex fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style InputSpecies fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style Validation fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style APIFormat fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style ValidationLog fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style DebugLog fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style SessionLog fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style Inputs fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style LogBeh fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
To render the reactive vals(), we define vals_out() with @render.text and include a ‘debug’ level log to review/investigate any issues.
@render.text
def vals_out():
data = vals()
logging.debug(f"Displaying input values to user - Session: {session_id}")
return f"{data}"- 1
-
Define
vals_out()for rendering
- 2
-
Dependency on reactive calculation (automatically updates when
vals()changes) - 3
-
Debug logging of user interactions for monitoring
- 4
- Simple string conversion
Predicted Mass
The Predicted Mass is really the heart of the application, and it’s definitely the most complicated reactive value in the server. The full definition is below, but we’ll dive into each level of logging in the following sections.
show/hide pred() reactive
@reactive.calc
@reactive.event(input.predict)
def pred():
"""Prediction with logging"""
request_start = time.time()
data_to_send = vals()
logging.info(f"Starting prediction request - Session: {session_id} - request_data: {json.dumps(data_to_send)}")
try:
print(f"\n=== PREDICTION REQUEST ===")
print(f"Sending data to API: {data_to_send}")
r = requests.post(api_url, json=data_to_send, timeout=30)
response_time = time.time() - request_start
# update performance metrics
# (keep for internal tracking)
current_times = request_times()
current_times.append(response_time)
if len(current_times) > 10:
current_times = current_times[-10:]
request_times.set(current_times)
print(f"HTTP Status Code: {r.status_code}")
print(f"Raw response text: {r.text}")
if r.status_code == 200:
result = r.json()
print(f"✅ Success! Parsed response: {result}")
# handle different possible response formats
if '.pred' in result:
prediction = result['.pred'][0]
elif 'predict' in result:
prediction = result['predict'][0]
else:
logging.warning(f"Unexpected response format - Session: {session_id} - response: {result}")
return f"Unexpected response format: {result}"
logging.info(f"Prediction successful - Session: {session_id} - response_time: {response_time:.3f}s - prediction: {prediction}")
# performance warning
if response_time > 5:
logging.warning(f"Slow API response - Session: {session_id} - response_time: {response_time:.3f}s")
return prediction
else:
error_msg = f"API Error {r.status_code}: {r.text}"
logging.error(f"Prediction request failed - Session: {session_id} - status: {r.status_code} - response: {r.text[:200]}")
error_count.set(error_count() + 1)
return error_msg
except requests.exceptions.ConnectionError as e:
error_msg = f"Connection Error: {str(e)}"
logging.error(f"API connection refused during prediction - Session: {session_id} - error: {str(e)}")
connection_errors.set(connection_errors() + 1)
error_count.set(error_count() + 1)
print(f"❌ Connection Error: {e}")
return error_msg
except requests.exceptions.Timeout:
error_msg = "Request timed out - API may be overloaded"
logging.warning(f"API timeout during prediction - Session: {session_id}")
timeout_errors.set(timeout_errors() + 1)
error_count.set(error_count() + 1)
return error_msg
except Exception as e:
error_msg = f"Error: {str(e)}"
logging.error(f"Unknown prediction error - Session: {session_id} - error: {str(e)}")
error_count.set(error_count() + 1)
print(f"❌ Error: {e}")
return error_msgThe @reactive.calc and @reactive.event(input.predict) decorators override the standard reactive behavior so the pred() function only executes when the Predict button is clicked (rather than whenever any input changes). This allows users to adjusting input parameters without sending accidental API calls (and ensures predictions only happen when the user explicitly requests a response).
@reactive.calc
@reactive.event(input.predict)
def pred():
"""Prediction with logging"""
request_start = time.time()
data_to_send = vals()
logging.info(f"Starting prediction request - Session: {session_id} - request_data: {json.dumps(data_to_send)}")- 1
-
Stacking these decorators creates a lazy evaluation with manual trigger, where the
pred()function is reactive (cached) (but only executes on explicit events).
- 2
-
Docstring for function purpose.
- 3
-
Provides precise millisecond-level stat time of API request.
- 4
-
Values to be sent to the API.
- 5
-
The f-string combines
{session_id}(prints session ID) and{json.dumps(data_to_send)}(converts the Python data structure into a JSON string) for logging.
This combines the performance benefits of caching with the user control of manual triggering:
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph TD
subgraph Dec["<strong>Decorator Stack</strong>"]
subgraph CalcDec["<strong>@reactive.calc</strong>"]
Event("<strong>@reactive.event(input.predict)</strong>")
Function("<strong>def pred()</strong>")
Event --"<em><strong>@reactive.calc</strong> checks caching layer</em>"--> Function
end
end
ButtonClick("User clicks <strong>Predict</strong>")
EventTrigger[Event decorator activates]
ExecuteFunction[Function executes]
CacheResult("<strong>Result cached</strong>")
ButtonClick --> EventTrigger
EventTrigger --"<em>Caching Layer</em>"---> CalcDec
Function ---> ExecuteFunction
ExecuteFunction --> CacheResult
style ButtonClick fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style EventTrigger fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style Event fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style Function fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style ExecuteFunction fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style CacheResult fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style Dec fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style CalcDec fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
Error Handling
The error handling/logging for the inputs sent to the API (and the response) starts with try and attempts to handle all possible return values.
Initial Request
The predictions are stored in r and sent using requests.post(), which includes:
- The destination (
api_url)
- Automatic conversion of Python dict to JSON format (
json)
- The maximum wait time in seconds (
timeout)
Performance Metrics Tracking
Performance timing is calculated using:
response_timeis the current time minus start time = elapsed seconds.
request_times()is a Shiny-specific reactive value - we can call it like a function to get its value.
current_times.append(response_time)adds current response time to the list of times.
The first if statement is a rolling window/circular buffer that focuses on the last 10 items and prevents the list from growing infinitely. Then the request_times is updated the stored value using set(current_times) (recall that request_times is a shiny-specific reactive value).
try:
print(f"\n=== PREDICTION REQUEST ===")
print(f"Sending data to API: {data_to_send}")
r = requests.post(api_url, json=data_to_send, timeout=30)
response_time = time.time() - request_start
current_times = request_times()
current_times.append(response_time)
if len(current_times) > 10:
current_times = current_times[-10:]
request_times.set(current_times)
print(f"HTTP Status Code: {r.status_code}")
print(f"Raw response text: {r.text}")- 1
-
Wrap risky code (like network requests) to catch and handle errors gracefully
- 2
-
Provides immediate visual feedback in the terminal/console (
logging.info()creates a permanent record in log file.)
- 3
-
HTTP
POSTrequest with timeout (POST(notGET) because we’re sending data to create/compute something)
- 4
-
Calculate how long the API request took.
- 5
-
Retrieve the current list of response times
- 6
- Add the current request’s time to the historical list
- 7
-
Keep only the 10 most recent measurements
- 8
-
Update the stored value
- 9
- See exactly what the API returned
The print statements give us an indication of what was returned in the HTTP status code:
200= Success! Everything worked.
400= Bad Request (you sent invalid data).
404= Not Found (wrong URL).
422= Validation Error (data format wrong).
500= Server Error (API crashed).
503= Service Unavailable (API overloaded).
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph LR
A("<strong>HTTP Status Codes</strong>") --> B("<code>2xx</code> Success")
A --> C("<code>4xx</code> Client Error")
A --> D("<code>5xx</code> Server Error")
B --> B1("<code>200</code> OK")
B --> B2("<code>201</code> Created")
C --> C1("<code>400</code> Bad Request")
C --> C2("<code>401</code> Unauthorized")
C --> C3("<code>404</code> Not Found")
C --> C4("<code>422</code> Validation Error")
D --> D1("<code>500</code> Internal Server Error")
D --> D2("<code>503</code> Service Unavailable")
style A fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style B fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style C fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style D fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style B1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style B2 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style C1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style C2 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style C3 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style C4 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style D1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style D2 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
Response Debugging
The error handling starts by checking the response code (200), r.json() is converted to a Python dictionary (result), then a confirmation message is printed if it’s successful. [0] is used to index the first element in the returned list and store the result in prediction:
if r.status_code == 200:
result = r.json()
print(f"✅ Success! Parsed response: {result}")
if '.pred' in result:
prediction = result['.pred'][0]
elif 'predict' in result:
prediction = result['predict'][0]
else:
logging.warning(f"Unexpected response format - Session: {session_id} - response: {result}")
return f"Unexpected response format: {result}"
logging.info(f"Prediction successful - Session: {session_id} - response_time: {response_time:.3f}s - prediction: {prediction}")
if response_time > 5:
logging.warning(f"Slow API response - Session: {session_id} - response_time: {response_time:.3f}s")
return prediction
else:
error_msg = f"API Error {r.status_code}: {r.text}"
logging.error(f"Prediction request failed - Session: {session_id} - status: {r.status_code} - response: {r.text[:200]}")
error_count.set(error_count() + 1)
return error_msg- 1
-
Only proceed if request succeeded
- 2
-
Convert JSON text to Python dictionary
- 3
-
Success confirmation with result
- 4
-
Handle different API response structures
- 5
-
Try second possible prediction format
- 6
-
Send error message back to UI instead of crashing
- 7
-
Structured success logging with metrics
- 8
- Performance threshold monitoring (5 seconds–configurable based on requirements)
- 9
-
Send prediction back to calling function for display
- 10
- Error message construction (non-200 status)
Structured Logs
If the returned prediction is anything other than result['.pred'][0] or result['predict'][0], the app returns a warning (not an error) because response succeeded but format is unexpected.
- Structured
logging.warning()Session: {session_id}= which user encountered this
response: {result}= what was received
If the returned prediction was successful, logging.info() returns an info log (i.e., a normal operational event, not a warning or error).
- Structured
logging.info()- Easier to parse/search logs
- Include metrics like average response time
- Debug issues by filtering by session ID
- Easier to parse/search logs
If the response time exceeds the performance threshold (5 seconds), a warning is returned (because the API works but isn’t optimal). This helps to identify performance degradation and helps diagnose API issues.
- Structured
logging.warning()- Identifies API server overload
- Tells us if the model taking too long to compute
- Can detect network latency issues
- Identifies API server overload
Finally, if the API returns a non-200 status, logging.error() returns a human-readable error description with the first 200 characters only ([:200]).
- Structured
logging.error()- Truncated error logging
- Prevents log files from bloating
- User has enough information to see why prediction failed
- Truncated error logging
In the console, the returned predictions display the following logs:
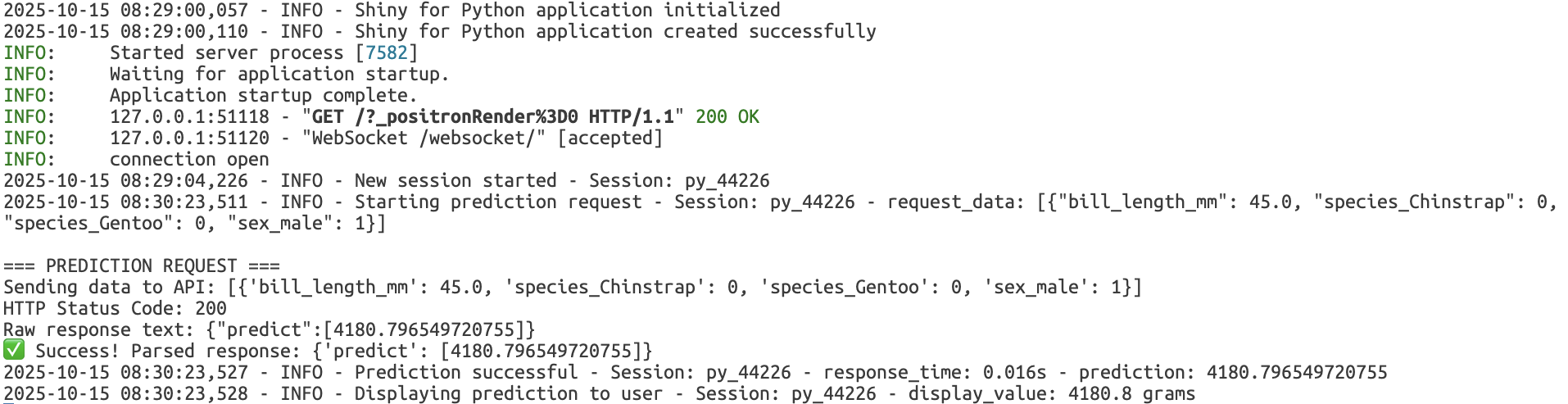
Exceptions
except requests.exceptions.ConnectionError as e:
error_msg = f"Connection Error: {str(e)}"
logging.error(f"API connection refused during prediction - Session: {session_id} - error: {str(e)}")
connection_errors.set(connection_errors() + 1)
error_count.set(error_count() + 1)
print(f"❌ Connection Error: {e}")
return error_msg- 1
-
Specific exception handling
- 2
-
Convert exception object to readable string
- 3
-
Contextual error logging
- 4
- Specific metric (how many connection failures?) or overall metric (total failures of any type?)
- 5
-
Console error notification
- 6
- Error return
The first exception uses the requests.exceptions. ConnectionError to catch connection failures separately from other errors.
- Exception
ConnectionError- The
error_msgstring is created usingstr(e)to extract the error description from exception.
- A structured
warninglog is printed to the console with thesession_idand the error description.
- The
except requests.exceptions.Timeout:
error_msg = "Request timed out - API may be overloaded"
logging.warning(f"API timeout during prediction - Session: {session_id}")
timeout_errors.set(timeout_errors() + 1)
error_count.set(error_count() + 1)
return error_msg- 1
-
Timeout-specific handling (from earlier
timeout=30)
- 2
-
User-friendly error message to explain probable cause to user
- 3
-
Warning-level logging (system still functional, just slow)
- 4
-
Dual counter tracking (can analyze if performance becomes a pattern)
- 5
- Error message returned
The second exception uses requests.exceptions.Timeout as a timeout threshold, which is triggered if the API doesn’t respond within 30 seconds.
- Exception
Timeout- Set with earlier
timeout=30argument
warning(noterror) because timeouts might be temporary
timeout_errors.set()anderror_count.set()can track timeout-specific metric plus total
- Set with earlier
except Exception as e:
error_msg = f"Error: {str(e)}"
logging.error(f"Unknown prediction error - Session: {session_id} - error: {str(e)}")
error_count.set(error_count() + 1)
print(f"❌ Error: {e}")
return error_msg- 1
- Catch-all exception handler
The final exception uses a generic Exception to handle any unexpected errors not caught above with ConnectionError or Timeout.
- Exception
Exception- Catch-all exception handler
- Only increments
error_count, not a specific counter
- Exception order matters (i.e., more specific exceptions must be caught first)
- Catch-all exception handler
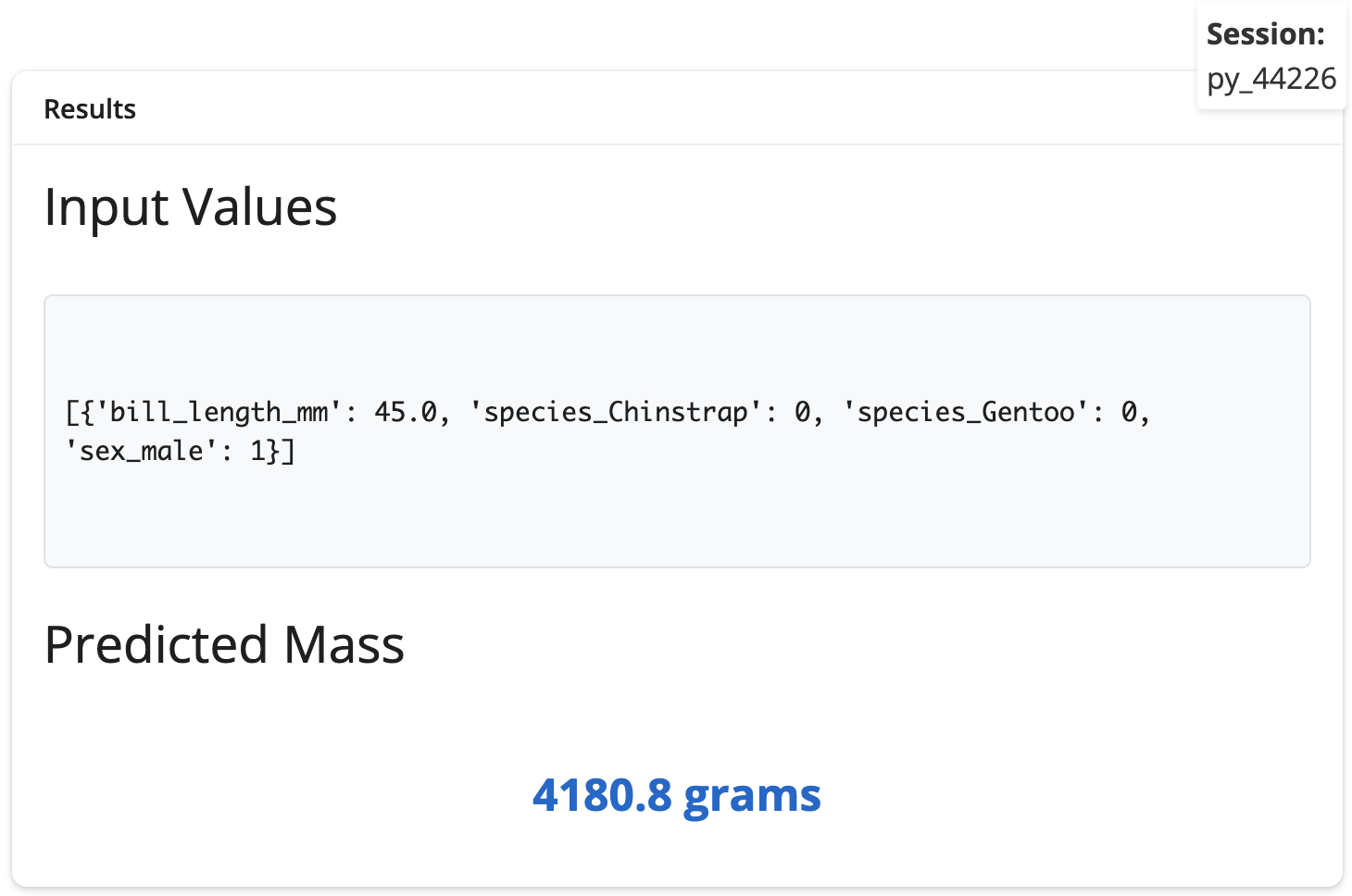
The @render.text decorator defines the pred_out() function, which doesn’t receive the prediction value as a parameter. Instead, it calls pred() directly, creating an implicit reactive dependency.
@render.text
def pred_out():
result = pred()
if isinstance(result, (int, float)):
display_value = f"{round(result, 1)} grams"
logging.info(f"Displaying prediction to user - Session: {session_id} - display_value: {display_value}")
return display_value
else:
return str(result)- 1
- Creates reactive dependency
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
flowchart TD
subgraph ErrFlow["<strong>Error Flow</strong>"]
APIRetError("<strong>API returns<br>error</strong>")
StringResult("<strong>pred()</strong><br>returns string")
TypeCheck("<strong>isinstance()</strong><br>check fails")
DirectDisplay("Display<br>error")
end
subgraph ErrDisp["<strong>Errors Displayed</strong>"]
ConnError("<em><strong>Connection<br>Error: ...</strong></em>")
TimeoutError("<em><strong>Request timed<br>out...</strong></em>")
APIError("<em><strong>API Error<br>500: ...</strong></em>")
FormatError("<em><strong>Unexpected<br>response format</strong></em>")
end
APIRetError --> StringResult
StringResult --> TypeCheck
TypeCheck --> DirectDisplay
DirectDisplay --> ConnError
DirectDisplay --> TimeoutError
DirectDisplay --> APIError
DirectDisplay --> FormatError
style APIRetError fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style StringResult fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style TypeCheck fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style DirectDisplay fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style ConnError fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style TimeoutError fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style APIError fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style FormatError fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style ErrFlow fill:#fbf7ec,stroke:#D2562B,color:#1B2A41
style ErrDisp fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
This means the render function automatically re-executes whenever the prediction function returns a new value. We use @render.text to render the predicted values returned from the API and include a logging.info() log with an f-string for the session_id and display_value:
System Status
The system status ui.card() contains the status of the API connection, a display of the recent app logs, and a date for “last updated.”
UI
Each section is stored in a ui.div() inside ui.layout_columns(). We can arrange each section by rows if we set a single column width to 12. The recent log display and last updated sections also contain CSS styling.
ui.card(
ui.card_header("System Status & Monitoring"),
ui.card_body(
ui.layout_columns(
ui.div(
ui.h5("API Connection:"),
ui.br(),
ui.output_text("api_status"),
ui.br(),
ui.h5("Recent Application Logs:"),
ui.div(
ui.output_text("recent_logs_display"),
style="font-family: 'Monaco', 'Courier New', monospace; font-size: 14px; background-color: #f8f9fa; padding: 10px; border-radius: 5px; max-height: 250px; overflow-y: auto; border: 1px solid #dee2e6; white-space: pre-wrap;"
),
ui.p(
"Last updated: ",
ui.output_text("log_timestamp"),
style="margin-top: 5px; color: #6c757d; font-size: 12px;"
)
),
col_widths=[12]
)
)
)- 1
-
Container for the three sections
- 2
-
Single width for entire area
- 3
-
API health check
- 4
-
Recent logs display
- 5
- Timestamp for last updated
- 6
- CSS styling for log display
API Health Check
The UI displays the API health check with a ui.output_text():
ui.h5("API Connection:"),
ui.br(),
ui.output_text("api_status")- 1
- Text output for API health check
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph TB
subgraph UI["UI Layer"]
A("<strong>ui.h5()</strong><br>header") --> B("<strong>ui.output_text()</strong>")
end
subgraph SERVER["Server Layer"]
C("<strong>@reactive.calc</strong><br>api_health_check") --> D("<strong>@render.text</strong><br>api_status")
end
subgraph API["API Layer"]
E("<strong>GET /ping</strong> endpoint")
end
B -.Displays.-> D
D -.Calls.-> C
C -.HTTP Request.-> E
E -.Response.-> C
style A fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style B fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style C fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style D fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style E fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style UI fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style SERVER fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
style API fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
The server contains a corresponding @reactive.calc and defines the api_health_check() with the following error catching:
@reactive.calc
def api_health_check():
"""Enhanced API health check with logging"""
try:
logging.debug(f"Checking API health - Session: {session_id}")
start_time = time.time()
r = requests.get(ping_url, timeout=5)
response_time = time.time() - start_time
if r.status_code == 200:
logging.info(f"API health check successful - Session: {session_id} - response_time: {response_time:.3f}s")
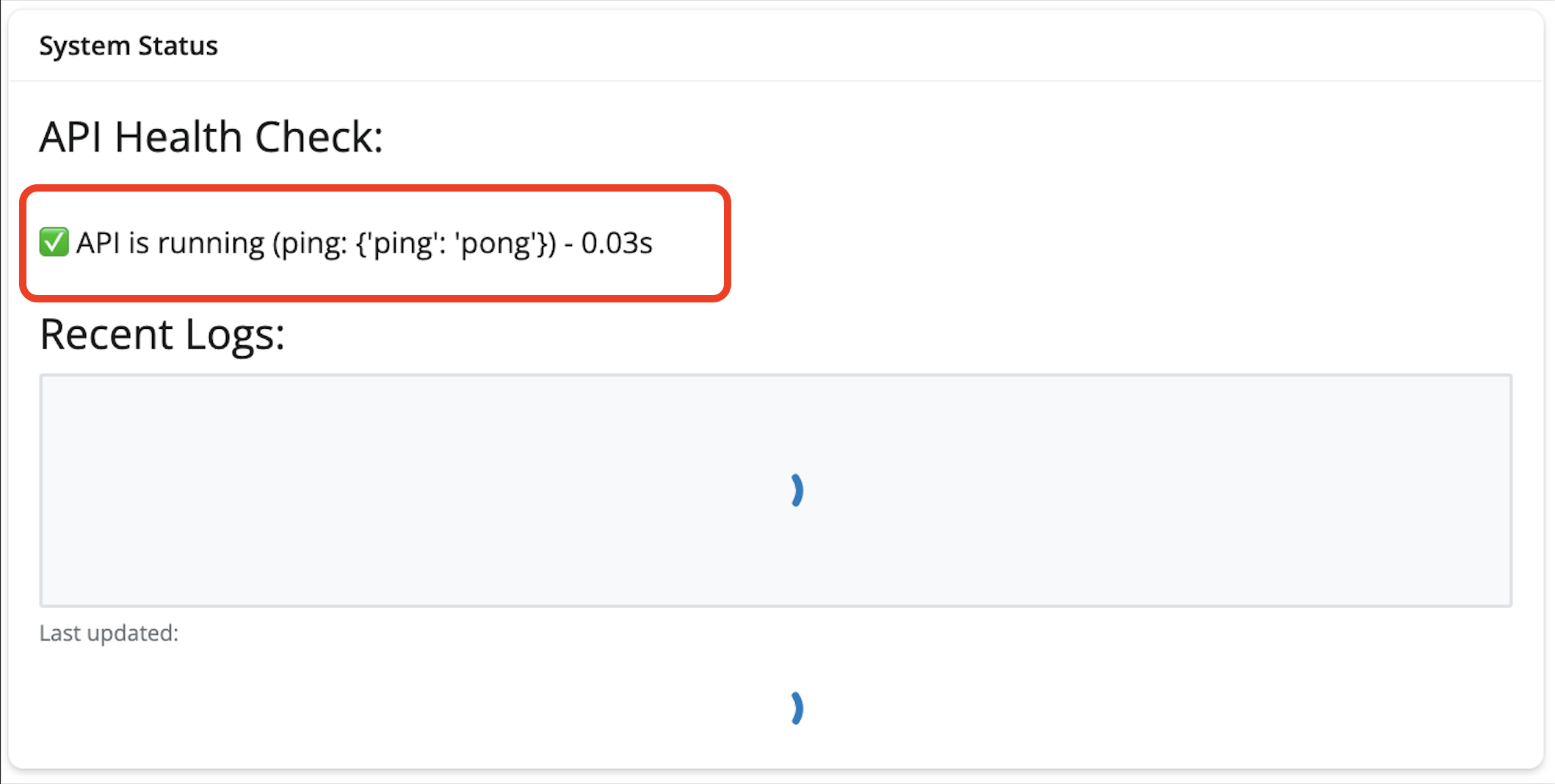
return f"✅ API is running (ping: {r.json()}) - {response_time:.2f}s"
else:
logging.warning(f"API ping failed - Session: {session_id} - status: {r.status_code}")
return f"⚠️ API ping failed: {r.status_code}"- 1
-
Reactive calculation decorator
- 2
- Docstring (documentation string describing function purpose)
- 3
-
Debug log entry with session ID
- 4
-
start_timeis the timer initialization (when operation begins) - 5
-
ris the HTTP GET request with timeout
- 6
-
response_timecontains the elapsed time calculation
- 7
-
Success: verified API responded positively
- 8
- Failure: non-success status handling
Structured Logs
When a health check is performed, logging.debug() creates a debug log to track when health checks occurred.
- Structured
logging.debug()debug= detailed diagnostic information
- Includes troubleshooting info
- Typically disabled in production
When a health check is successful (HTTP code == 200), logging.info()
- Structured
logging.info()info= Normal operational event
- Record successful health check with timing
- Baseline for performance comparison
When a health check fails to return a non-200 HTTP status, logging.warning() creates
- Structured
logging.warning()warning= API responded but not with success
- Unusual but non-critical responses
except requests.exceptions.ConnectionError as e:
logging.error(f"API connection refused - Session: {session_id} - error: {str(e)}")
return "❌ Cannot connect to API - is it running on port 8080?"
except requests.exceptions.Timeout:
logging.warning(f"API health check timeout - Session: {session_id}")
return "⚠️ API health check timeout"
except Exception as e:
logging.error(f"API health check failed - Session: {session_id} - error: {str(e)}")
return f"❌ API health check failed: {str(e)}"- 1
-
The
ConnectionErrorexception with the error and session id
- 2
-
The
Timeoutexception with the session id
- 3
- The general exception with error message and session id
Exceptions
The first exception uses the requests.exceptions. ConnectionError to catch connection failures separately from other errors.
- Exception
ConnectionErrorstr(e)is used to extract the error description from exception.
- The
warninglog is printed to the console with thesession_idand the error description.
The second exception uses requests.exceptions.Timeout as a timeout threshold, which is triggered if the API doesn’t respond within 30 seconds.
- Exception
Timeout- Set with earlier
timeout=30argument
warning(noterror) because timeouts might be temporary
- Set with earlier
The final exception uses a generic Exception to handle any unexpected errors not caught above with ConnectionError or Timeout.
- Exception
Exception- Catch-all exception handler
- Handle any unforeseen errors gracefully
- Exception order matters (i.e., more specific exceptions must be caught first)
- Catch-all exception handler
The code above continuously checks if the API server is responding, like calling a phone number to see if someone answers. The @render.text decorator converts the returned value to a string, sends it to the UI, and automatically re-renders it when the dependencies (i.e., values) change.
@render.text
def api_status():
return api_health_check()- 1
-
Output rendering decorator
- 2
-
Function name must match UI’s
output_text("api_status")
Below is a sequence diagram illustrating the ping sent to the API, the logs generated, and the other possible (un-healthy) responses:
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
sequenceDiagram
autonumber
participant UI as UI
participant Render as @render.text<br>api_status()
participant Calc as @reactive.calc<br>api_health_check()
participant Log as Logging
participant API as API
Note over UI: User opens<br>app
UI->>Render: Request api_status display
Render->>Calc: Call api_health_check()
Calc->>Log: DEBUG: Checking API health
Calc->>Calc: Record start_time
Calc->>API: GET http://127.0.0.1:8080/ping<br>(timeout=5s)
alt Success (200 OK)
API-->>Calc: 200 {"message": "pong"}
Calc->>Calc: Calculate response_time
Calc->>Log: INFO: Health check successful<br>response_time: 0.15s
Calc-->>Render: "✅ API is running... 0.15s"
else Non-200 Status
API-->>Calc: 404 / 500 / 503
Calc->>Log: WARNING: Ping failed<br>status: 404
Calc-->>Render: "⚠️ API ping failed: 404"
else ConnectionError
API--xCalc: Connection refused
Calc->>Log: ERROR: Connection refused
Calc-->>Render: "❌ Cannot connect to API..."
else Timeout
Note over API: Processing...<br>(>5 seconds)
Calc--xAPI: Timeout!
Calc->>Log: WARNING: Timeout
Calc-->>Render: "⚠️ API health check timeout"
else Unknown Error
API--xCalc: Unexpected error
Calc->>Log: ERROR: Unknown error
Calc-->>Render: "❌ API health check failed: ..."
end
Render-->>UI: Display status message
Note over Calc: Cache result<br>(auto-refresh<br>periodically)
loop Every N seconds
Calc->>API: GET /ping (again)
API-->>Calc: Response
Calc-->>Render: Updated status
Render-->>UI: Update display
end
In the app, we can see the response rendered in the System Status:
Recent Application Logs
In the UI contains the following CSS styling variables to make it look like the console:
font-family
font-size
background-color
padding
border-radius
max-height
overflow-y
border
white-space
ui.h5("Recent Application Logs:"),
ui.div(
ui.output_text("recent_logs_display"),
style="font-family: 'Monaco', 'Courier New', monospace; font-size: 14px; background-color: #f8f9fa; padding: 10px; border-radius: 5px; max-height: 250px; overflow-y: auto; border: 1px solid #dee2e6; white-space: pre-wrap;"
)- 1
-
div()for recent log display
- 2
-
Text display of recent logs
- 3
- CSS styling for log output (similar to console)
Below is an overview of recent log display architecture:
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph TB
subgraph UI["UI"]
subgraph H5["ui.h5() Header"]
subgraph DIV["ui.div() Container"]
C("<strong>ui.output_text()</strong><br>display")
end
end
end
subgraph SERVER["Server"]
D("<strong>@reactive.file_reader()</strong><br>reads<br><strong>log_file_content</strong>") --> E("<strong>@render.text</strong><br>recent_logs_display")
end
subgraph FS["File System"]
F("<strong>shiny_app.log</strong><br>file")
end
subgraph WRITE["Log Writers"]
G("Application Events") -.Triggers.-> H("<strong>logging.info/<br>error/<br>etc</strong>")
H --"Writes to"--> F
end
C -.Displays.-> E
E -.Calls.-> D
D -.Watches.-> F
F -.Changes trigger.-> D
style C fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style D fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style E fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style F fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style G fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style H fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff
style UI fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style H5 fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style DIV fill:#fbf7ec,stroke:#5B8C5A,color:#1B2A41
style SERVER fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
style FS fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
style WRITE fill:#fbf7ec,stroke:#2A6F77,color:#1B2A41
In the server, we define log_file_content(), which watches the file and re-runs function when it’s modified. The file is safely opened using open() and the f mode means read only (we do this so the file will automatically close).
f.readlines() reads the entire file as a list (each line is an element in the list) and returns it in a dictionary with the last_modified (when it was read) and the total_lines (total number of lines in the log file).
@reactive.file_reader(log_file_path)
def log_file_content():
"""Monitor log file for changes"""
try:
with open(log_file_path, 'r') as f:
lines = f.readlines()
return {
'lines': lines,
'last_modified': datetime.now(),
'total_lines': len(lines)
}
except Exception as e:
logging.error(f"Error reading log file - Session: {session_id} - error: {str(e)}")
return {
'lines': [],
'last_modified': datetime.now(),
'total_lines': 0
}- 1
-
Reactive file monitoring (automatically detect when log file changes)
- 2
-
Docstring documenting function purpose
- 3
-
Context manager for file handling
- 4
-
Safely open file
- 5
-
Read entire file as list
- 6
-
Dictionary return with metadata
- 7
-
Generic exception
- 8
-
errorlog for graceful degradation
- 9
- Return empty dictionary with identical elements.
The exception is generic and returns an error and safe default if log file can’t be read.
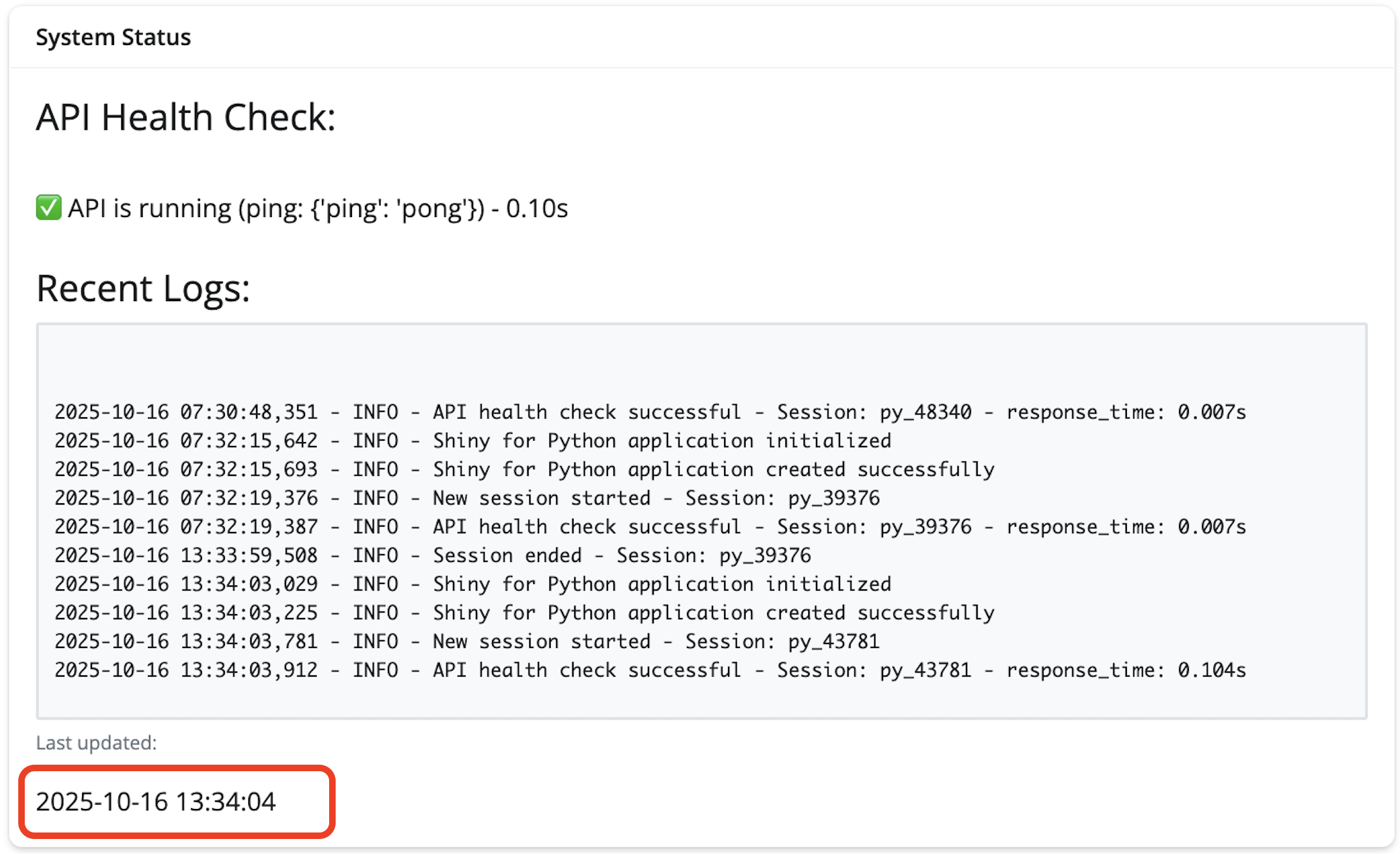
For rendering, we get the last 10 lines for better monitoring and remove the whitespace with line.rstrip(). Before returning the logs, we combine the list of lines into single string with line breaks. A debug log is created the logs have been updated with the session id and the length (number of lines) of the recent logs. If there are no logs, a message is returned.
@render.text
def recent_logs_display():
log_data = log_file_content()
lines = log_data['lines']
if lines:
recent_lines = lines[-10:] if len(lines) > 10 else lines
clean_lines = [line.rstrip() for line in recent_lines]
logging.debug(f"Updating recent logs display - Session: {session_id} - showing {len(recent_lines)} lines")
return '\n'.join(clean_lines)
else:
return "No logs available yet..."- 1
-
Text render decorator
- 2
-
Define
recent_logs_display()function (matches UI’soutput_text("recent_logs_display"))
- 3
-
Call reactive dependency and create
log_datafromlog_file_content()
- 4
-
Extract
linesfromlog_data
- 5
-
Truthiness check (handle empty log file case)
- 6
-
Slice last 10 lines
- 7
-
Remove trailing whitespace (especially
\n)
- 8
-
debug= detailed trace information
- 9
-
Join lines with newlines
- 10
- Provide clear message when no logs exist
Below is a sequence diagram illustrating the log configuration, log file creation/storage, app initialization, and log file monitoring, reading, and display:
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
sequenceDiagram
autonumber
participant App as App Code
participant Log as Log File<br>(shiny_app.log)
participant Watcher as @reactive.file_reader
participant Content as log_file_content()
participant Display as recent_logs_display()
participant UI as User Interface
Note over App: App starts,<br>logs events
App->>Log: logging.info("Started")
App->>Log: logging.error("Failed")
Note over Watcher: Monitoring<br>begins
Watcher->>Log: Watch for changes
Display->>Content: Request log data
Content->>Log: open(log_file_path, 'r')
Log-->>Content: ['INFO - Started\n', 'ERROR - Failed\n']
Content->>Content: Return dict with<br>lines, timestamp, count
Content-->>Display: log_data
Display->>Display: Extract lines
Display->>Display: Slice last 8 lines
Display->>Display: Strip whitespace
Display->>Display: Join with '\n'
Display-->>UI: "INFO - Started\nERROR - Failed"
UI->>UI: Display in styled div
Note over App: New<br>event<br>occurs
App->>Log: logging.warning("Slow API")
Log->>Watcher: File modified event!
Watcher->>Content: Invalidate & re-execute
Content->>Log: Read file again
Log-->>Content: Updated lines
Content-->>Display: New log_data
Display->>Display: Process again
Display-->>UI: Updated display
Note over UI: User sees<br>new log<br>automatically!
After launching the app, we can see the 10 most recent log entries in the log file (including the previous app launches).

Last updated
In the UI, the last updated section includes a CSS styled text output:
ui.p(
"Last updated: ",
ui.output_text("log_timestamp"),
style="margin-top: 5px; color: #6c757d; font-size: 12px;"
)- 1
-
Text output for timestamp
- 2
- CSS styling for date
In the server, the log_file_content() is used to extract the last_modified date, which is formatted before returning to the UI.
@render.text
def log_timestamp():
log_data = log_file_content()
return log_data['last_modified'].strftime("%Y-%m-%d %H:%M:%S")- 1
-
Render decorator for timestamp
- 2
-
Match the UI portion (
ui.output_text("log_timestamp"))
- 3
-
Reactive dependency for
log_file_content()
- 4
-
Return formatted data with
strftime()
The formatted date is rendered under the Last updated section at the bottom of the display.
Finishing touches
To finish off our app, we’ll include a README.md with instructions for launching the API and application together and capture dependencies.
python3 -m pip freeze > requirements.txtThe final files in the do4ds-labs/_labs/lab04/Python folder are below:
├── app-log.py
├── logs
│ └── shiny_app.log
├── Python.Rproj
├── README.md
└── requirements.txt
2 directories, 5 files- 1
-
App python script
- 2
-
Log file
- 3
-
RStudio project file
- 4
-
Documentation for app
- 5
- Dependencies
I’ve included a few more mermaid diagrams illustrating the topics covered in this lab.
Logging Levels Decision Tree
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
graph LR
A("Event") --> B{"What happened?"}
B -->|Normal operation| C("<strong>logging.info()</strong>")
B -->|Unexpected but recoverable| D("<strong>logging.warning()</strong>")
B -->|Failed operation| E("<strong>logging.error()</strong>")
B -->|System crash imminent| F("<strong>logging.critical()</strong>")
B -->|Detailed troubleshooting| G("<strong>logging.debug()</strong>")
C --> C1("Examples:<br>1. Prediction successful<br>2. Session started")
D --> D1("Examples:<br>1. Slow response<br>2. Unexpected format<br>Timeout")
E --> E1("Examples:<br>1. Connection refused<br>2. HTTP error<br>Parse failure")
F --> F1("Examples:<br>1. Out of memory<br>2. Database corrupted")
G --> G1("Examples:<br>1. Variable values<br>2. Detailed flow")
style A fill:#5B8C5A,stroke:#000000,stroke-width:1px,color:#ffffff
style B fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style C fill:#2A6F77,stroke:#000000,stroke-width:1px,color:#ffffff
style D fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style E fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style F fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style G fill:#D2562B,stroke:#000000,stroke-width:1px,color:#ffffff
style C1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff,text-align:left
style D1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff,text-align:left
style E1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff,text-align:left
style F1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff,text-align:left
style G1 fill:#1B2A41,stroke:#000000,stroke-width:1px,color:#ffffff,text-align:left
Timeout vs ConnectionError
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
sequenceDiagram
participant App as Health Check
participant Network
participant API
Note over App,API: Scenario 1: Connection Error
App->>Network: Try to connect
Network--xAPI: Cannot reach (port closed/firewall)
Network-->>App: ConnectionError
Note over App,API: Scenario 2: Timeout
App->>Network: Try to connect
Network->>API: Connection established
App->>API: GET /ping
Note over API: Processing...<br>(taking too long)
Note over App: 5 seconds pass...
App--xAPI: Give up waiting
App->>App: Timeout exception
Log file monitoring overview
Below is a diagram illustrating how the configured logs are updated in the application and displayed in the UI:
%%{init: {'theme': 'base', 'themeVariables': {'fontFamily': 'monospace'}}}%%
sequenceDiagram
autonumber
participant User
participant ShinyUI as Shiny UI
participant ShinyServer as Shiny Server
participant Logger as Logging System
participant API as FastAPI
participant Model as Model
User->>ShinyUI: Enters penguin data<br>(bill=45mm, species=Gentoo, sex=Male)
ShinyUI->>ShinyServer: Input values change
ShinyServer->>Logger: Log input values
User->>ShinyUI: Clicks "Predict" button
ShinyUI->>ShinyServer: Trigger prediction
ShinyServer->>Logger: Log prediction request start
ShinyServer->>API: POST /predict<br>{"bill_length_mm": 45.0,<br>"species_Gentoo": 1, ...}
API->>API: Validate input format
API->>Model: Pass data to model
Model->>Model: Calculate prediction
Model->>API: Return prediction (e.g., 4500.0)
API->>ShinyServer: HTTP 200<br>{".pred": [4500.0]}
ShinyServer->>Logger: Log successful prediction<br>(response time, result)
ShinyServer->>ShinyUI: Update display:<br>"4500.0 grams"
ShinyUI->>User: Shows prediction
Note over ShinyServer,Logger: Simultaneously monitoring
Logger->>ShinyUI: Update recent logs display
Shiny for Python HTML tag objects.↩︎
Formatted string literals “let you include the value of Python expressions inside a string by prefixing the string with
forFand writing expressions as{expression}.”↩︎