install.packages('ellmer')
# or the dev version
pak::pak('tidyverse/ellmer')30 🏗 btw
We previously used the chores package to develop helpers—pre-written prompts—for repetitive tasks such as creating roxygen2 documentation and updating testthat tests.1 In the gander chapter, we used an addin to send code and the IDE/environment context to the LLM.2
Both chores and gander assist us in automating and enhancing the prompts we’re sending to the LLM. These packages use addins and/or shortcuts to streamline prompts, provide additional context, and creates an experience that doesn’t require us to leave our development environment.3
In this chapter we’ll focus on the btw package, which is fundamentally different than chores and gander because it,
“provides a default set of tools to to peruse the documentation of packages you have installed, check out the objects in your global environment, and retrieve metadata about your session and platform.”4
I’ll cover using btw to improve the documentation and contents of the downloadable report in our sap application.
30.1 Configuration
Install ellmer and btw:
install.packages("btw")
# or the dev version
# install.packages("pak")
pak::pak("posit-dev/btw")We can place the btw configuration options in the .Rprofile (similar to other ellmer configurations).5
I’ve added a project-level .Rprofile file this branch of the sap package and included a system_prompt and model:
if (interactive()) {
require(ellmer, quietly = TRUE)
}
if (interactive()) {
require(btw, quietly = TRUE)
}
options(
btw.client = ellmer::chat_anthropic(
system_prompt =
"You are an expert R/Python programmer who loves explaining complex topics to non-technical audiences.
...",
model = "claude-sonnet-4-5-20250929"
)
)- 1
-
Ensure
ellmerpackage
- 2
-
Ensure
btwpackage
- 3
-
btwconfig
- 4
-
System prompt for all conversations with chat
- 5
-
modelargument for most current Claude model
I’ve included the full system prompt below in an easier to read format:
Launch app with the shinypak package:
launch('30_llm-btw')30.2 Context files
Along with a system prompt, we’ll want to introduce a comprehensive context file.6 Context files are markdown documents located in the root directory (similar toREADME.md files) that agents read automatically before doing work. Generally speaking, these files answer the question, “What do I need to know to be productive?”
Think of these docs as the LLM’s analogue of an onboarding document for a new developer on your team. Good things to include are the project’s purpose, audience, conventions and constraints (i.e., gotchas, “don’t touch X”, etc.). Without any context, the LLM has to “rediscover” the project on every session, which wastes tokens because the model has to spend at least a few turns exploring the project’s files. btw comes with it’s own context file, btw.md.7
Let’s view the system and session context without a btw.md (or other context file). In the RStudio ![]() Console, we’ll use
Console, we’ll use btw_client() to create a btw-enhanced chat client.8
chat <- btw_client()We can view the btw enhancements by examining the chat object in the console:
chatWe can see btw has added sections for tools and skills before the system prompt we provided in ellmer::chat_anthropic() (we will cover tools and skills in more depth below). We can already see the benefit of having the system prompt loaded in the context because the model already has our instructions on the first turn (and we’ve spent $0).
30.3 btw tools
Broadly speaking, tools are functions a model can call. Tools have a name, description, and will run code that returns a result (i.e., list files and folders, read a file, execute R). Tools are always present in the model’s context — the model sees the full list and picks one when needed.
btw comes with a set of pre-defined tools for examining package documentation, environments, directories and files, git and GitHub, our development environment, CRAN packages, R sessions, and general web searches.9
30.4 btw.md
use_btw_md() function will create a boilerplate btw.md file.
use_btw_md(scope = "project")ℹ See btw::btw_client for format details
ℹ See btw::btw_tools for available tools
ℹ Call `btw::btw_task_create_btw_md()` to use an LLM to help you initialize the project context.This includes some default content for the project context:
“Use
btw.mdto inform the LLM of your preferred code style, to provide domain-specific terminology or definitions, to establish project documentation, goals and constraints, to include reference materials such or technical specifications, or more. Storing this kind of information inbtw.mdmay help you avoid repeating yourself and can be used to maintain coherence across many chat sessions.”
The YAML header in our newly created btw.md is where can specify the client (along with the provider and model).
---
client: claude/claude-sonnet-4-5-20250929
---The default values in btw.md will automatically use the latest Claude model from Anthropic. The YAML values above are similar to using ellmer’s chat_* functions.10
The tools section of the YAML header contains a list of the groups from btw_tools(). Each of these groups contains a collection of functions “that allow the chat to interface with your computational environment.”
---
tools:
- docs
- env
- files
- git
- github
- ide
- search
- session
- web
---Additional instructions are also provided on code style:
Follow these important style rules when writing R code:
* Prefer solutions that use {tidyverse}
* Always use `<-` for assignment
* Always use the native base-R pipe `|>` for piped expressions30.5 Creating btw.md
We’ll want to improve our generic btw.md context file. As the output above mentioned, we can call btw_task_create_btw_md() to start an interactive chat session to help us write our context file.11
btw_task_create_btw_md(client = "anthropic")This opens an interactive chat in the Viewer pane:
30.6 How tool calling works
When we start the interactive chat, the model informs us it will be examining the sap package contents for more information.
I'll begin by exploring the project structure to understand
what we're working with.The model can’t execute R code, but btw has “registered” a collection of tools (i.e., R functions) with the model, these can be used to help provide additional information. In other words, the btw_task_create_btw_md() function uses the tools in btw to add more project context to the btw.md file.
30.6.1 Registered tools
Let’s back up and take a look at the tools btw has registered with get_tools():
chat$get_tools()Each registered tool has a @name and @description parameter, with WHEN TO USE instructions written in markdown.
Recall the model was going to start by “exploring your project structure”, and we can see this aligns with the WHEN TO USE section of btw_tool_files_list():
$btw_tool_files_list
# <ellmer::ToolDef> btw_tool_files_list(path, type, regexp, `_intent`)
# @name: btw_tool_files_list
# @description: List files or directories in the project.
WHEN TO USE:
* Use this tool to discover the file structure of a project.
* When you want to understand the project structure, use `type = "directory"`
to list all directories.
* When you want to find a specific file, use `type = "file"` and `regexp` to
filter files by name or extension.
CAUTION: Do not list all files in a project, instead prefer listing files in
a specific directory with a `regexp` to filter to files of interest.30.6.2 Tool calls
In the Viewer pane, we can review each tool call and the results. Below is the first call to btw_tool_files_list():
btw_tool_files_list(path = ".", `_intent` = "List root directory to identify project type and structure")The function includes an _intent argument, where the model, “explain[s] why it called the tool.”13
30.6.3 Tool results
The tool returns a markdown-formatted table of the project contents (file/folder names, their size, and when they were last changed):14
| path | type | size | modification_time |
| ----------------- | --------- | ------- | ------------------- |
| DESCRIPTION | file | 621 | 2026-04-29 10:34:14 |
| NAMESPACE | file | 65 | 2026-04-29 09:46:28 |
| R | directory | 352 | 2026-04-29 10:35:32 |
| R/app_server.R | file | 689 | 2026-04-29 09:25:01 |
| R/app_ui.R | file | 492 | 2026-04-29 10:46:21 |
...omitted...30.6.4 Model response
The table result is sent to the model, which provides a summary of it’s contents:
Perfect! This is clearly an R Package with a Shiny application.
Let me read the key files to understand the project.30.6.5 Recap
I’ve created an overview of this tool call in the diagram below.15
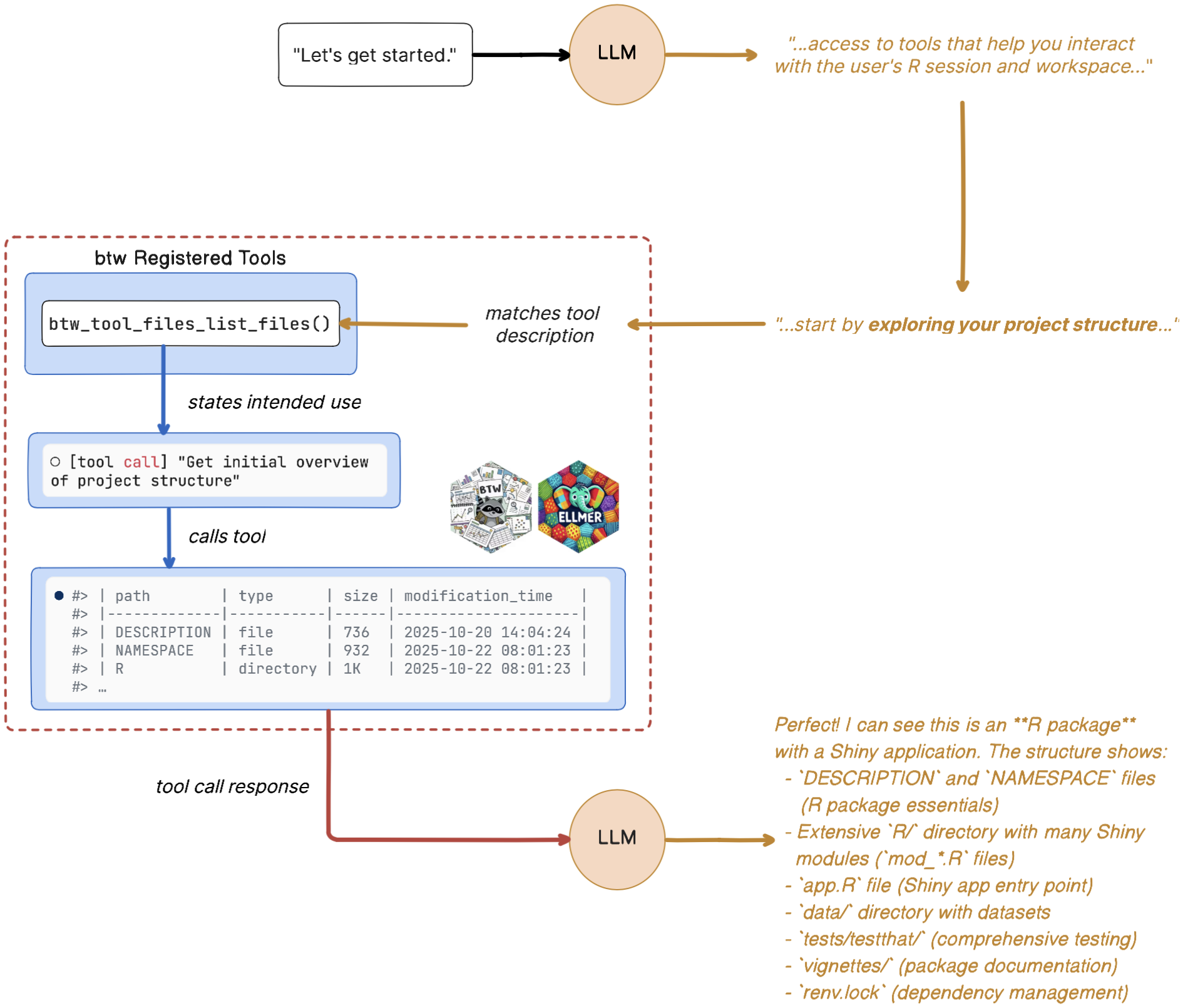
btwThe model context begins with our supplemented system prompt–which now includes the tools and skills at it’s disposal. When we begin, the model beings by exploring the project structure–matching the registered tool description for the btw_tool_files_list() function, which returns a table of the project contents. These tool results are sent to the model, and we see the overall summary.
30.7 Building the btw.md file
I strongly recommend reading the documentation on creating the btw.md.16 The instructions are broken into three phases:
- Phase 1: Strategic Exploration (Research & Discovery)
- Phase 2: Narrative Construction (User Collaboration)
- Phase 3: Documentation (File Writing)
Phase 1: Strategic Exploration
The first phase is the Strategic Exploration, and it’s goal is to efficiently understand the project’s structure, purpose, and technical architecture without overwhelming the context window. This includes using tools to identify key files, review documentation, and tailor the approach to the project type.
The phase 1 summary is what the model learned about the sap package using the btw tools (expand the callout box to view).
The model primarily relied on btw_tool_files_read() and btw_tool_docs_available_vignettes() to gather context on the project.
Phase 2: Narrative Construction
After the project summary, the model starts with the Narrative Construction. The overall goal of phase 2 is to collaborate with the user to provide key architectural context and the reasoning behind important design decisions, using brief, developer-focused explanations that aren’t in the existing documentation.
I’ve included the phase 2 questions and answers below (expand the callout box to view):
Phase 3: Documentation
After completing the phase 2, btw gives us a chance to review each section of our btw.md. You can review the entire conversation in the inst/prompts/setup.md file.
When Phase 2 is complete, we’re told we have a “comprehensive btw.md file” that is “structured from narrative (purpose and architecture) to reference material (technical details and workflows), making it easy for new developers to get oriented quickly while also serving as a practical guide for working with the project”.
View the complete updated btw.md file on GitHub.
To make sure btw reads the project context file, we’ll restart R, load, and install the sap package, then create another chat object with btw_client():
chat <- btw_client()
chatNow we can see the chat object includes 1) the system and session info, 2) the tool access description, 3) the entire btw.md file, and 4) our system prompt.
30.8 btw App
We’re now ready to launch the btw app:17
btw_app()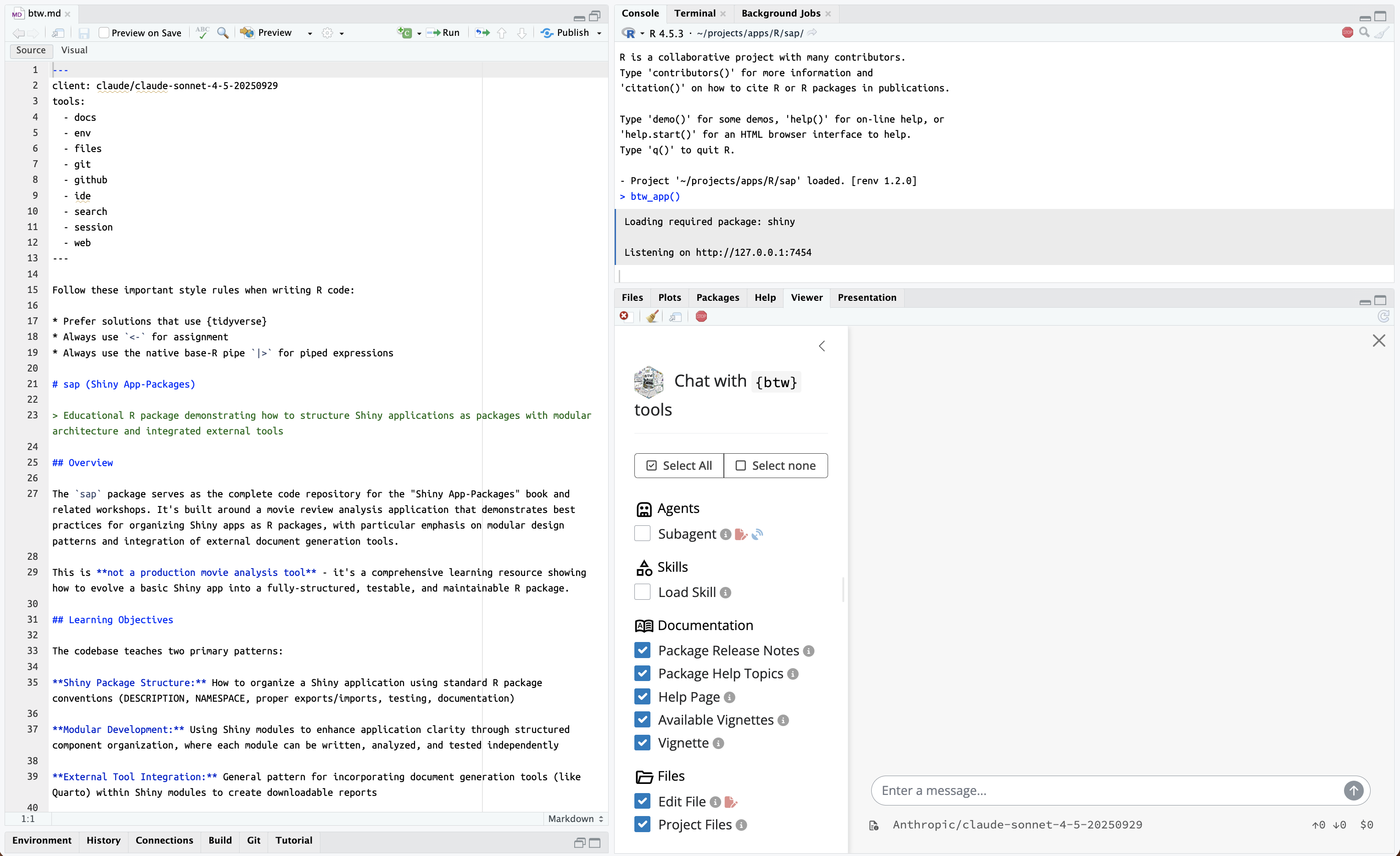
If we expand the sidebar, we can see the registered tools provided by btw:
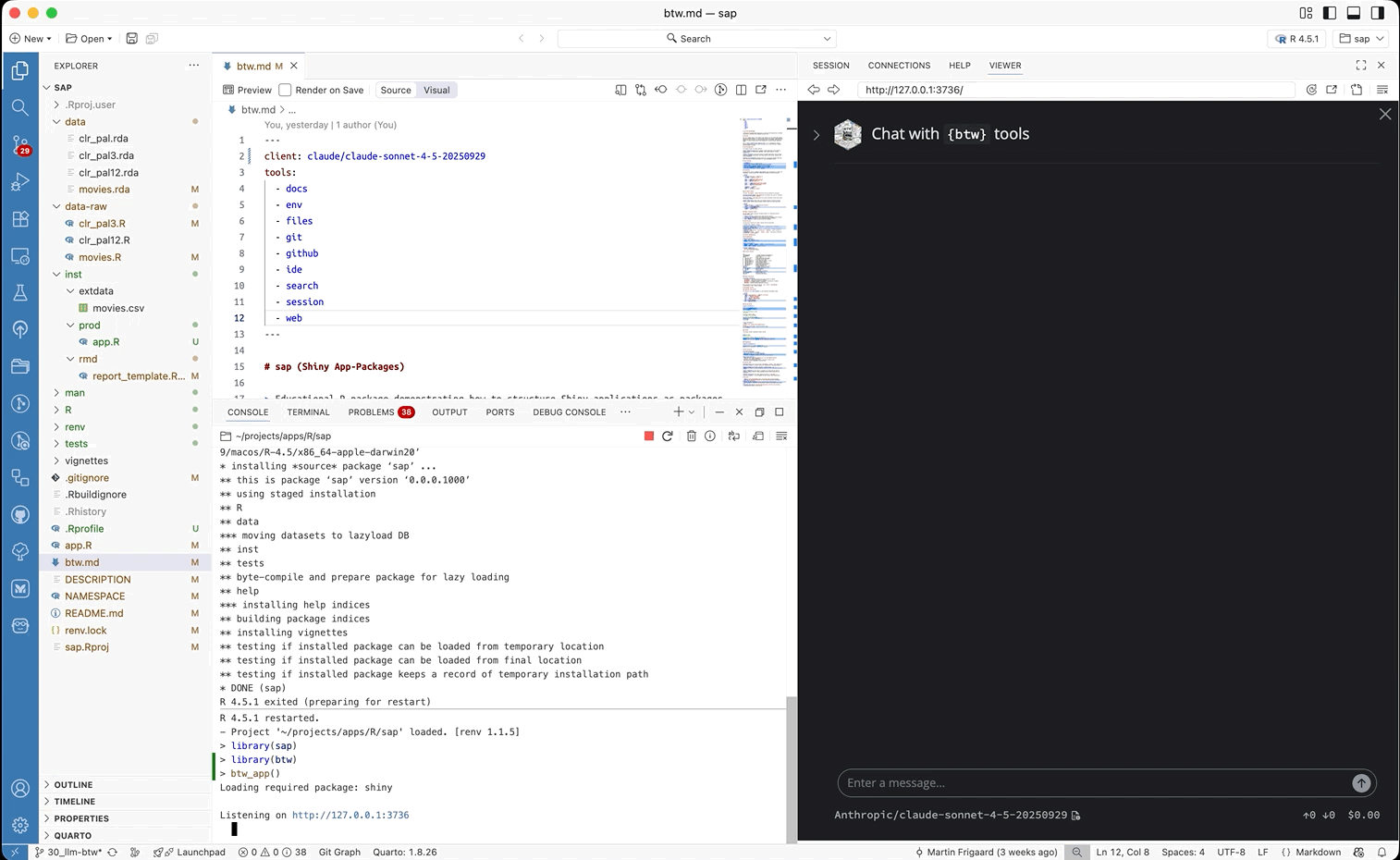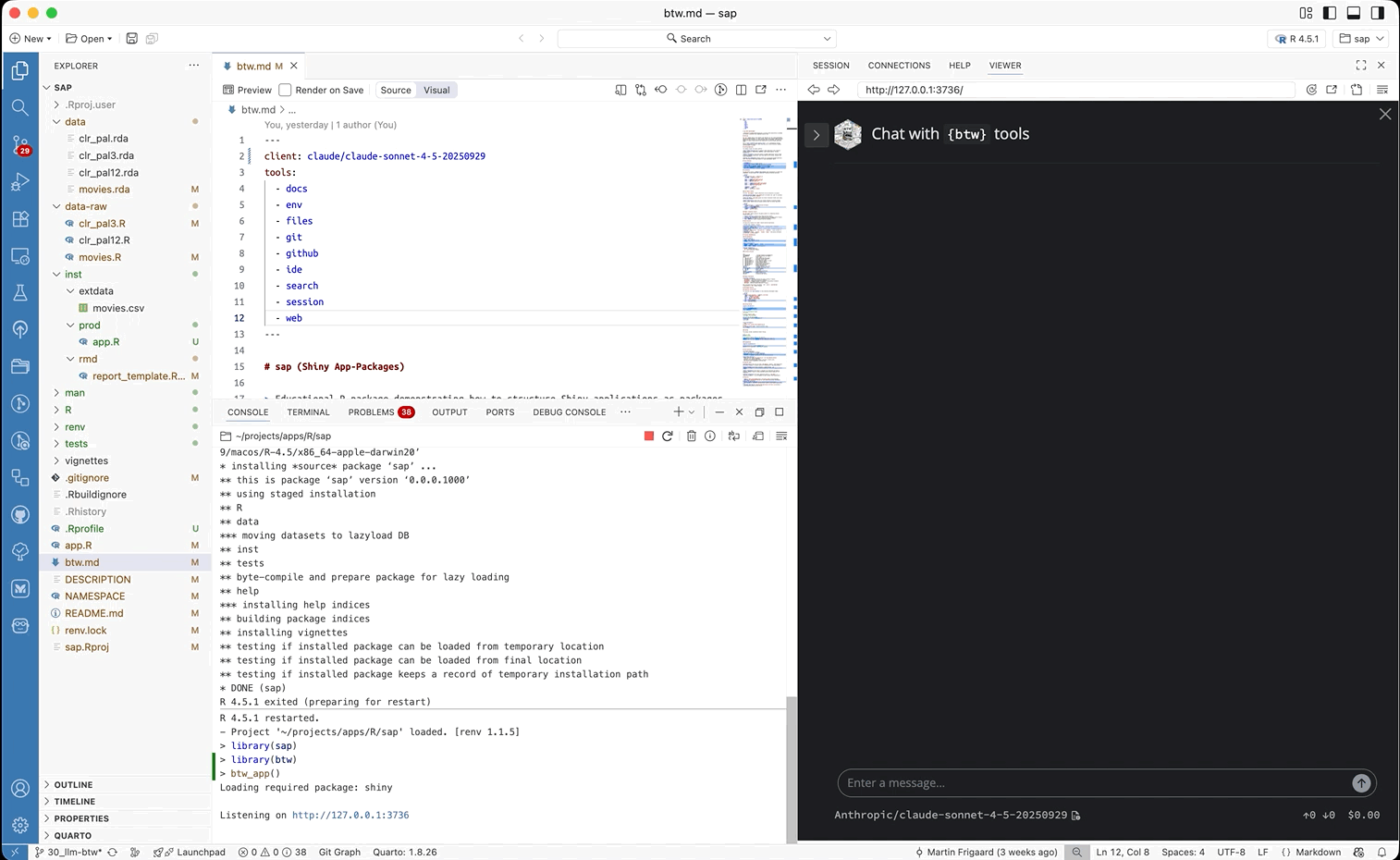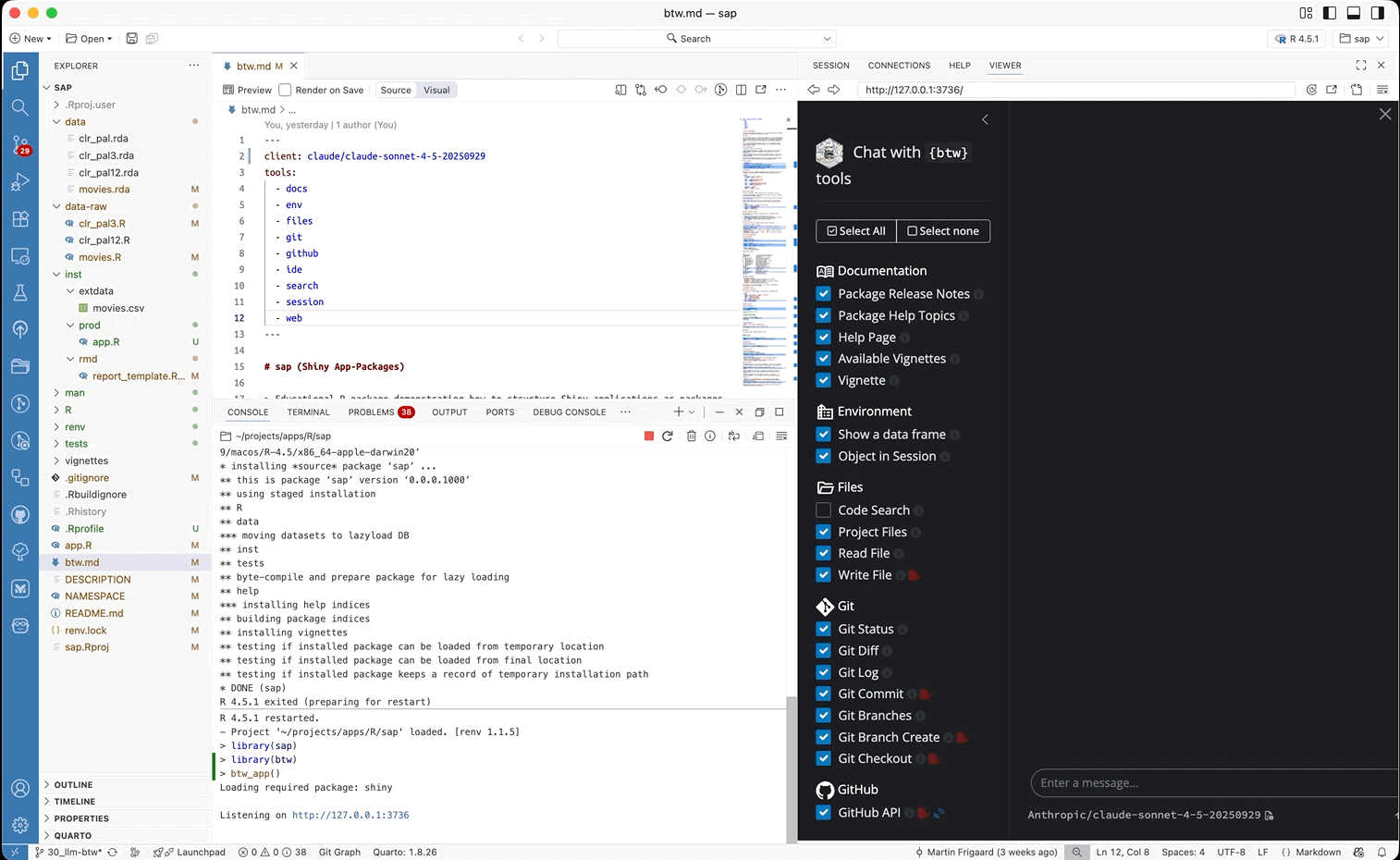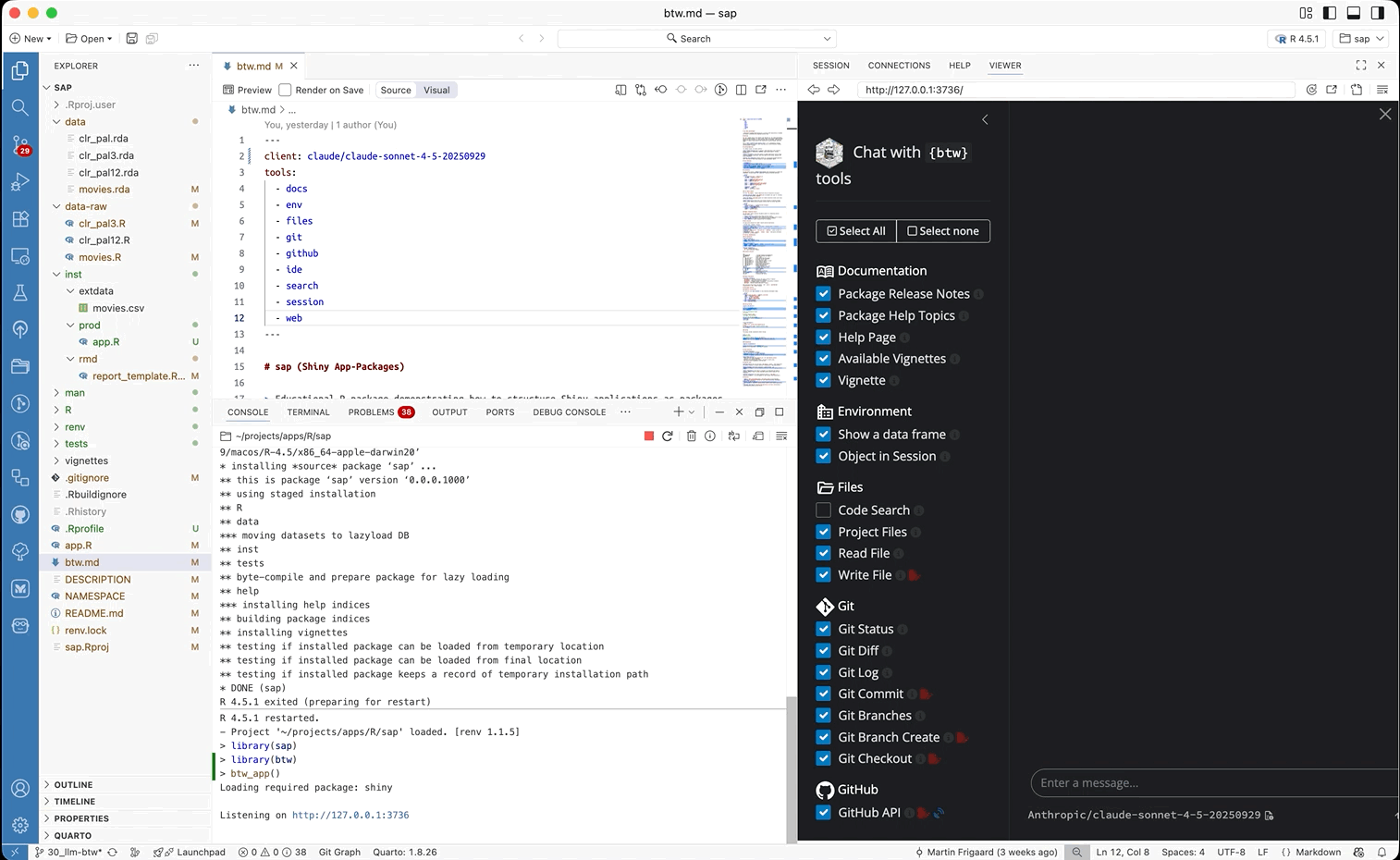
By default, the app includes all of the tools available from btw (with the exception of Subagent, Load skill, and Package Tools).18
30.8.1 Subagents
When I started using btw, I was somewhat new to LLMs, so it felt a bit like I’d been dropped into the deep end of the pool. Below I’ve tried to give some background on the questions I had when I started building subagents and skills.
btw_app()What is the difference between an agent and a subagent?
As we can see from the App interface, we’re able to add a Subagent to the available tools.19
Generally speaking, an agent is an LLM chat session that uses tools autonomously to complete tasks. A subagent is a specialized tool the agent can delegate subtasks to—like a manager (the Agent) assigning work to a specialist (the Subagent).
%%{init: {'theme': 'neutral', 'themeVariables': { 'fontFamily': 'monospace', "fontSize":"16px"}}}%%
flowchart TD
User(User) -->|prompt| Agt("Agent<br>(LLM + tools)")
Agt -->|delegates subtask| SubAgt("Subagent<br>(tool-shaped agent)")
SubAgt -->|result| Agt
Agt -->|final response| User
In btw, subagents are separately configured chat sessions — with their own models, system prompts, and toolsets — that can be invoked from the main session.
Subagents are defined in a markdown file with YAML frontmatter — not in an .R file. The frontmatter configures the agent, and the markdown body becomes it’s system prompt. btw auto-discovers these files and exposes them as tools to the main agent. We’ll create a subagent file in .btw/agent-code_reviewer.md and give it some instructions for reviewing code.
Below is the frontmatter for the code_reviewer subagent:
---
name: code_reviewer
description: Reviews R code for best practices...
title: Code Reviewer
icon: magnifying-glass
client: anthropic/claude-sonnet-4-20250514
tools:
- files
- docs
---- 1
-
How the subagent is invoked
- 2
-
Advertised to the parent
- 3
-
Subagent display name
- 4
-
UI hint
- 5
-
Which model runs it
- 6
- Tool groups it can call
We’ll also include some instructions and examples for how to style the code that differs from the standard tidyverse conventions. Expand the callout box below to view the entire description.
Now when we launch the btw_app(), we can see our Code Reviewer subagent.
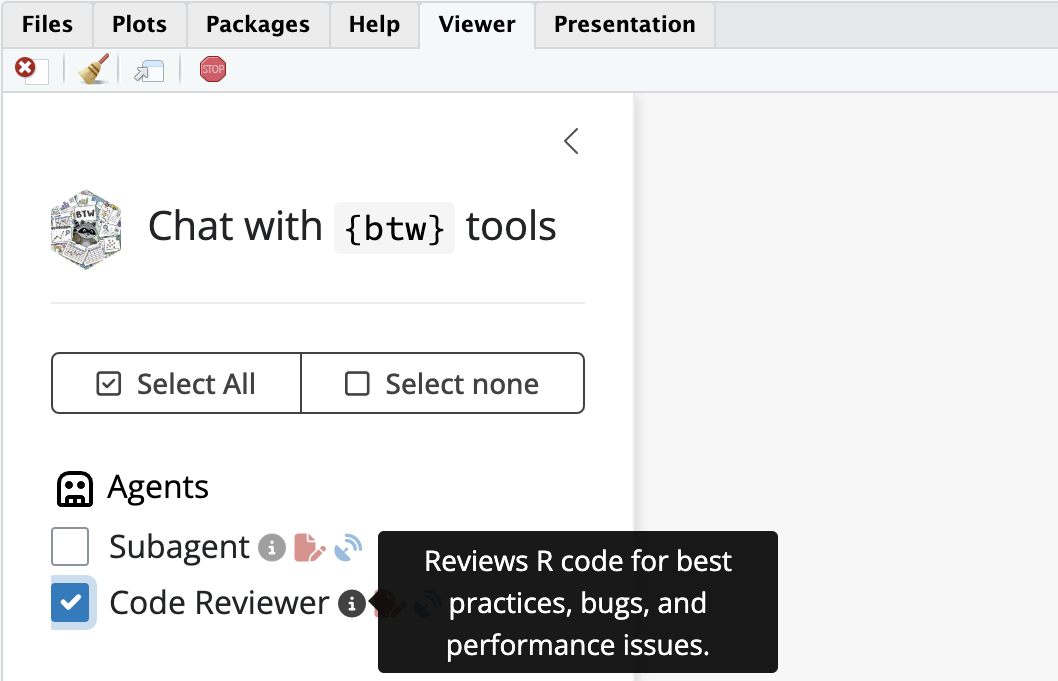
btw_app()Using the subagent
After selecting our subagent in the app UI, we’ll ask the model to review the code using code_reviewer:
‘Review the code using the code_reviewer subagent.’
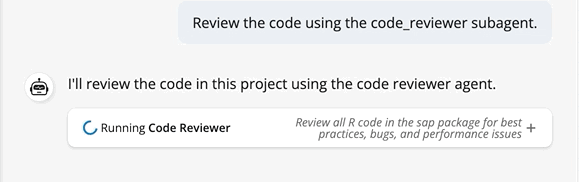
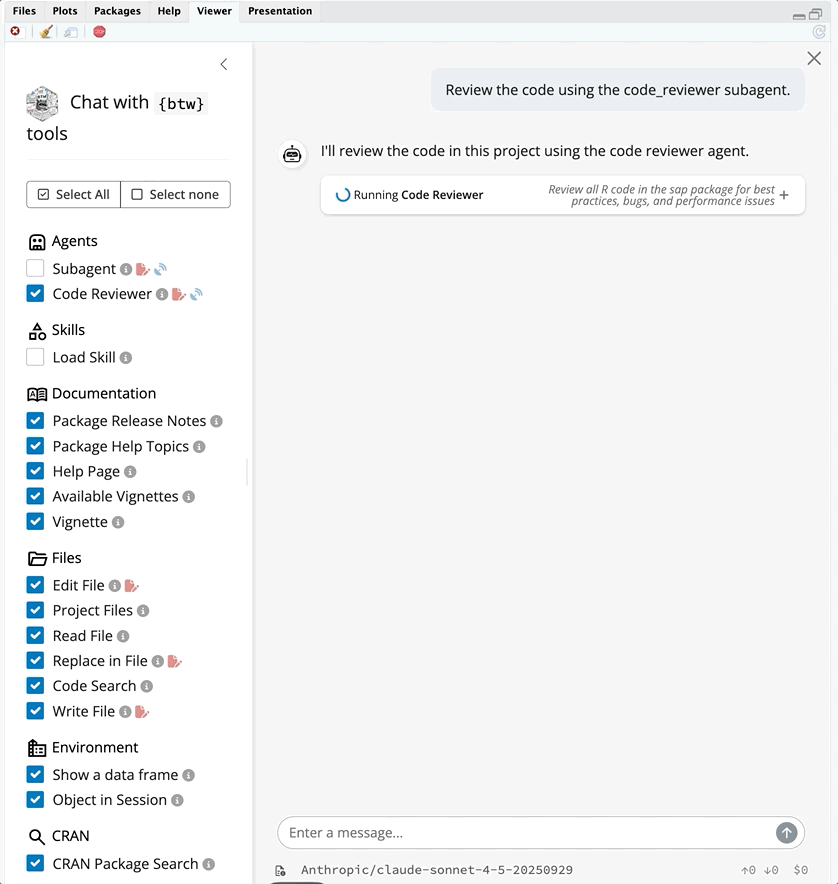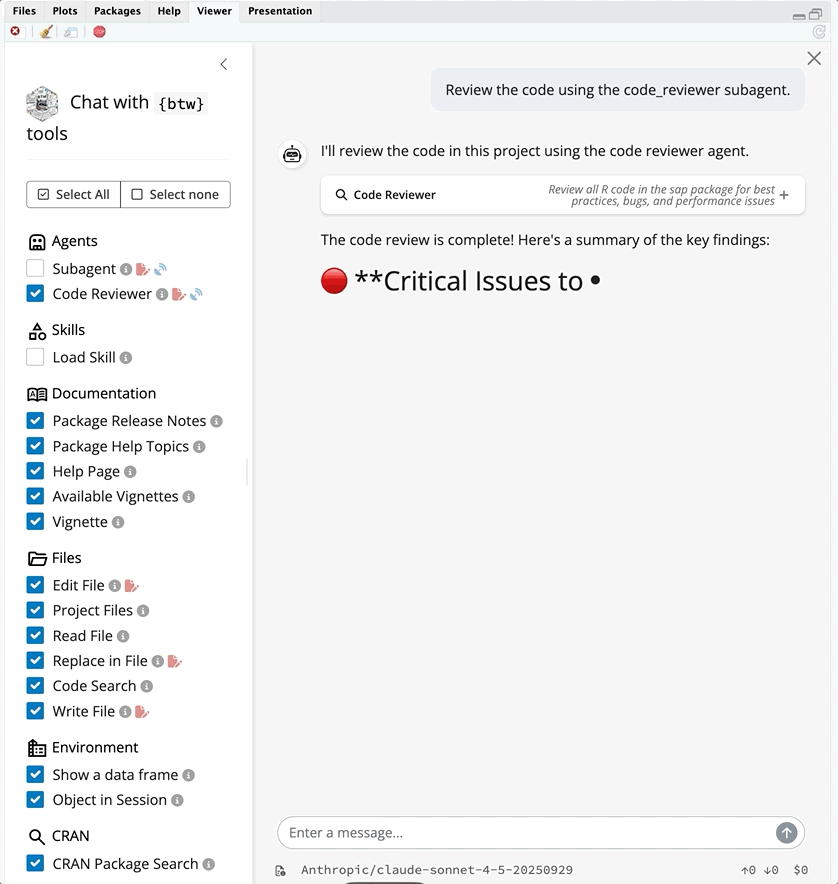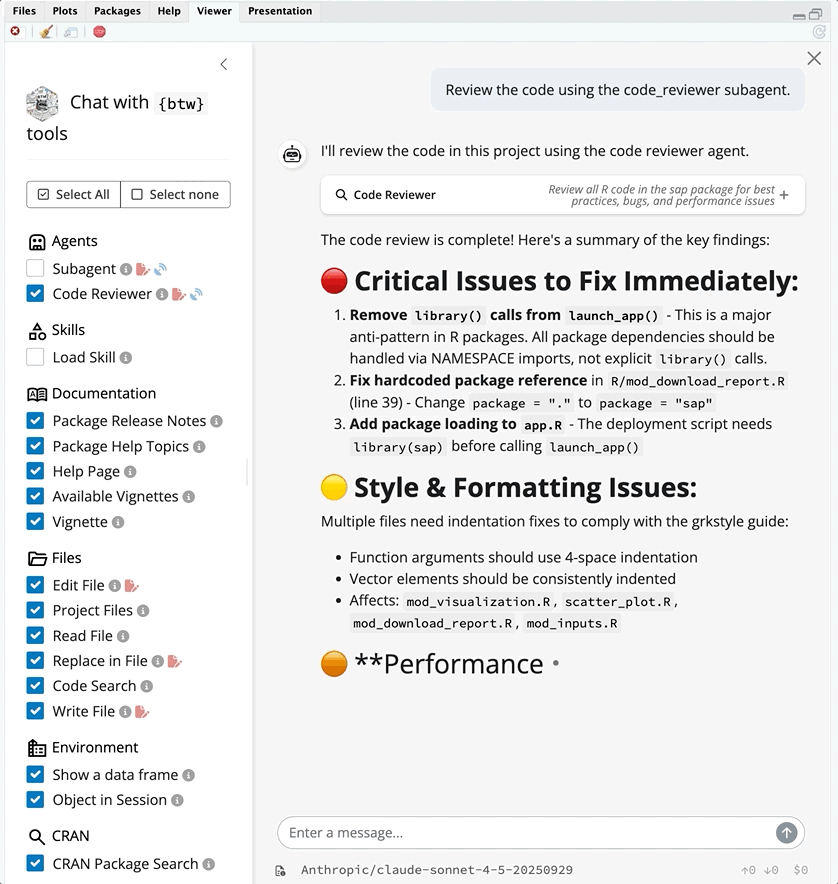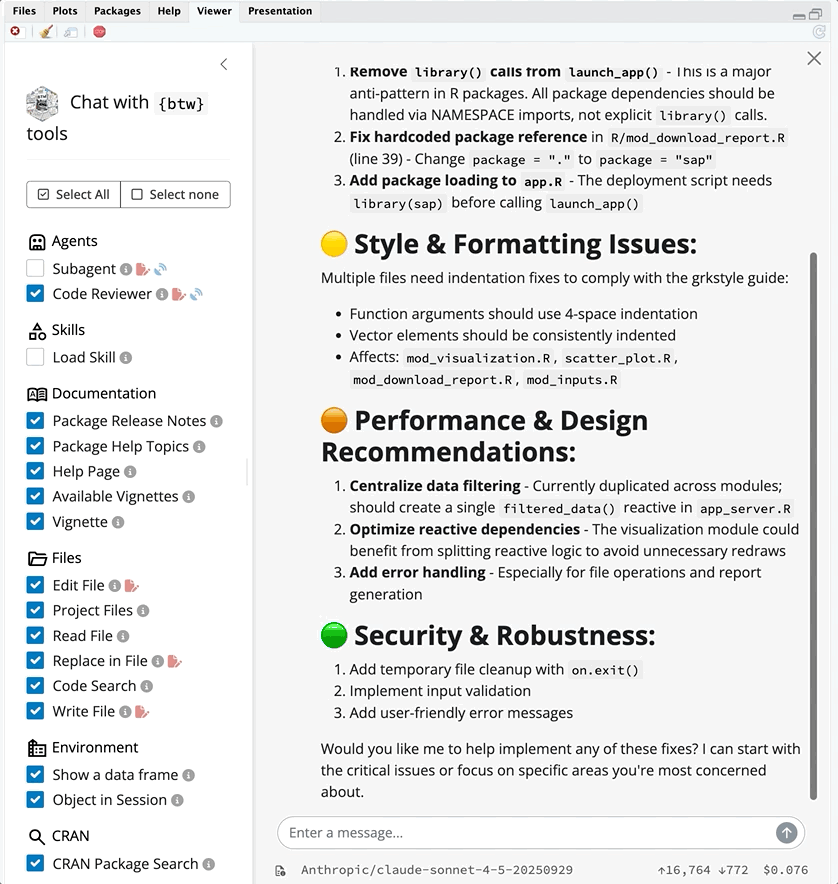
code_reviewer subagent in btw_app()This prompt is sent from the parent chat, which sees the code_reviewer subagent as a single tool call. After sending the prompt, the code_reviewer subagent runs its own multi-turn loop using its own tools.
If we expand the Running Code Reviewer box, we can see the session ID (stable_sparrow) for the subagent context window and the prompt sent to the subagent:
%%{init: {'theme': 'neutral', 'themeVariables': { 'fontFamily': 'monospace', "fontSize":"16px"}}}%%
flowchart TD
User[User in main chat] --> ParentChat["Parent<br><code>btw_client</code>"]
ParentChat -->|btw_tool_agent| Subagent["<code>code_reviewer</code><br>subagent"]
Subagent -->|reads YAML + body| Spec["<code>agent-code_reviewer.md</code>"]
Subagent -->|calls files/docs tools| Project["Project files & R docs"]
Subagent -->|returns review text| ParentChat
ParentChat --> User
The code_reviewer subagent invocation starts with a fresh context window. This keeps the parent chat’s history from leaking in, and the intermediate work performed by the code_reviewer doesn’t leak out. When used this way, the code_reviewer can read all the project’s files without bloating the parent chat’s context.
What is the subagent doing?
I’ve stored the tool calls from the code_reviewer subagent on GitHub,20 but the image below captures what’s happening:
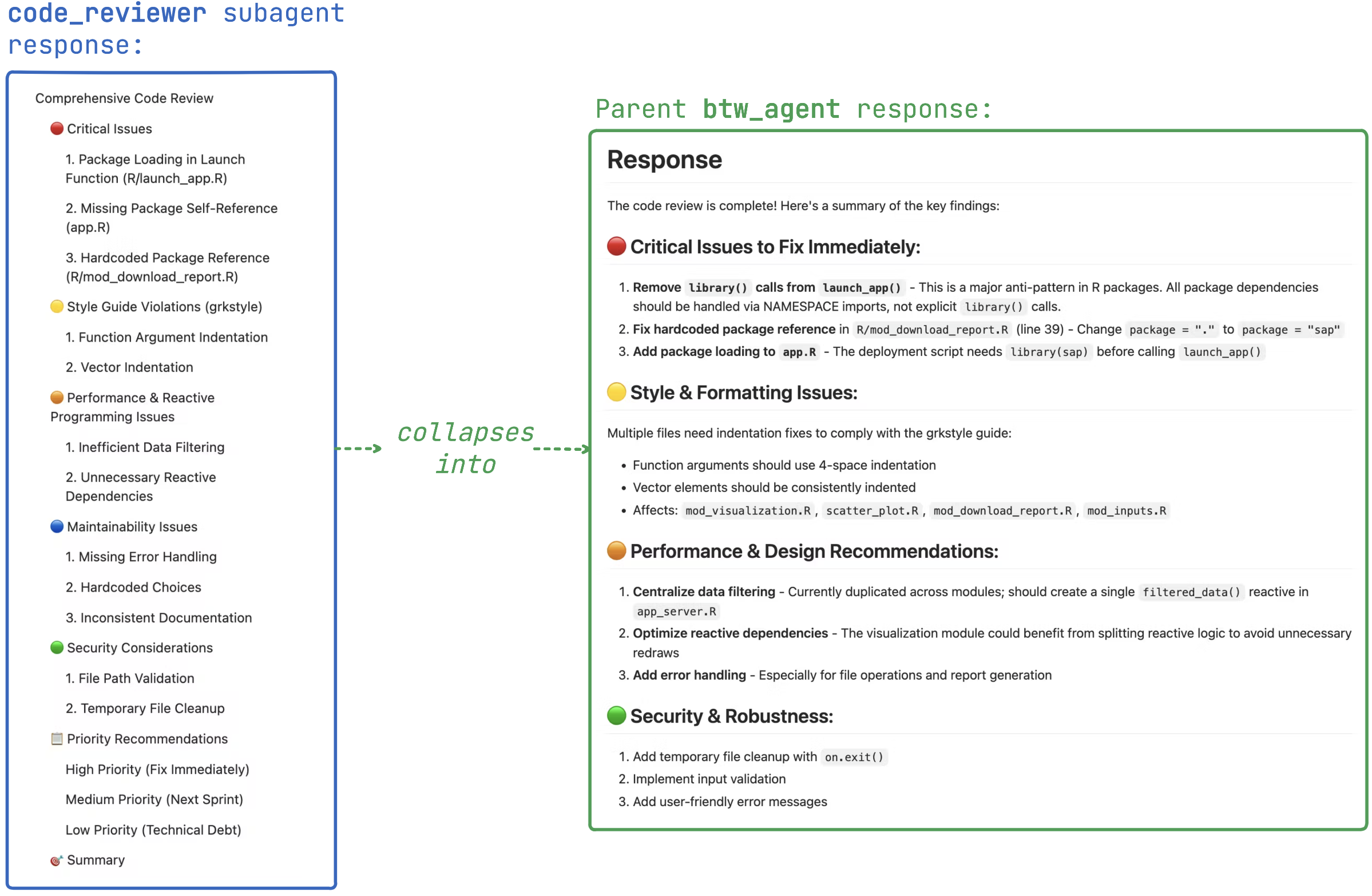
The parent chat never sees the intermediate tool calls — only the final summary (which it summarizes again before returning a response).
code_reviewer subagent response in btw_app()See the full-code_review-2026-04-29.md file for the prompt, tool calls, and summary from the subagent.
30.8.2 Skills
In the btw_app(), we can see we have an option to load a skill and it’s “bundled resources.”
btw_app()If you recall, the initial btw.md referenced how skills can be used/accessed (expand the callout box below to read the skills section from btw.md)
Below we’ll cover what skills are, how they compare to tools and subagents, and how to create them.
What are skills?
Skills are markdown files with instructions for the model on how to approach a task (i.e., domain-specific expertise). Skills are loaded “on demand”–and don’t execute anything–so they don’t consume context until they’re needed.
This aligns with the skills section in the chat client–it has instructions and the location of skill-creator/SKILL.md to “provide detailed guidance for specific tasks.”
How are skills different than tools and subagents?
I’ve found a good way to think about the differences between tools and skills is,
“Tools pay rent, skills pay only when you visit.”
The prompt directory is where
choresstores the helpers used in the addin.↩︎This is explained in What is gander actually doing?↩︎
The addins are an improvement over chatting with
live_console(chat)orlive_browser().↩︎This description of
btwactually comes from themcptoolsdocumentation.↩︎Recall that the
.Rprofilefile can exist at the user and/or the project-level. You can easily open this file withusethis::edit_r_profile().↩︎There is a push to standardize these files across platforms.↩︎
If you’re already using a context file (i.e.,
AGENTS.mdorllms.txt), these can be configured with inbtw_client().↩︎An
ellmer::Chatclient which provides a “sequence of user and assistant Turns sent to a specific Provider.”↩︎Read a complete list of available tools from
btwin the package documentation.↩︎For more information on
clientvalues, read the Chat Settings documentation.↩︎The prompts used in this project are stored in
inst/prompts/(as we learned in theellmerchapter).↩︎We can register tools using
ellmer’screate_tool_def()andtool()functions.↩︎The
_intentargument is “An optional string describing the intent of the tool use. When the tool is used by an LLM, the model will use this argument to explain why it called the tool.”↩︎I’ve cleaned up the formatting on this markdown table so it’s easier to read, but it’s an output you might expect from the
fspackage.↩︎This image was inspired by the tool calling overview presented in Garrick Aden-Buie’s genAI 2025: Using LLMs in Shiny presentation.↩︎
To run the
btw_app(), make sure you have the latest version ofshinychat.↩︎Subagents are defined with
btw_tool_agent_subagent(), Load skill usesbtw_tool_skill(), and the Package Tools include functions for loading code, running R CMD check, generating documentation, running package tests, and computing test coverage.↩︎I recommend reading the documentation from
btwon subagents.↩︎Both the comprehensive review from the subagent and the tool calls are in the inst/prompts/ folder.↩︎