library(dplyr)
head(dplyr::storms)
## # A tibble: 6 × 13
## name year month day hour lat long status
## <chr> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <fct>
## 1 Amy 1975 6 27 0 27.5 -79 tropi…
## 2 Amy 1975 6 27 6 28.5 -79 tropi…
## 3 Amy 1975 6 27 12 29.5 -79 tropi…
## 4 Amy 1975 6 27 18 30.5 -79 tropi…
## 5 Amy 1975 6 28 0 31.5 -78.8 tropi…
## 6 Amy 1975 6 28 6 32.4 -78.7 tropi…
## # ℹ 5 more variables: category <dbl>, wind <int>,
## # pressure <int>,
## # tropicalstorm_force_diameter <int>,
## # hurricane_force_diameter <int>7 Data
The previous chapters in this section covered how documenting functions and managing dependencies. In this chapter, we’ll discuss how data files (like movies.RData) become part of an app-package so they can be loaded into our application. We’ll also cover the various locations and purposes for app-package data files.
Data in R packages are typically stored in one of three folders: data/, data-raw/, and inst/extdata/.1 The folder you use will depend on the format, accessibility, and intended purpose of the data file.2
7.1 The data/ folder
The primary location for data is the data/ folder. Objects in data/ folder are available in your package namespace when it’s installed and loaded, and can be accessed with the :: syntax. See the example below of the storms data from dplyr:
7.1.1 LazyData
Data files become part of a package when they’re added to the data/ folder and LazyData: true is added to the DESCRIPTION file. Enabling LazyData means the data are only loaded into memory if they are explicitly accessed by the user or a function in the package. Until then, only the dataset name is loaded. This user-friendly practice is the default for most R packages.
Omitting LazyData (or setting it to false) means we would have to access the data file from the package by explicitly loading it with the data() function.
7.1.2 use_data()
The usethis::use_data() function simplifies adding data to packages. To use usethis::use_data(), we can load the data into the global environment with load("movies.RData"), then run usethis::use_data(movies):
usethis::use_data(movies)✔ Adding R to Depends field in DESCRIPTION.
✔ Creating data/.
✔ Setting LazyData to "true" in DESCRIPTION.
✔ Saving "movies" to "data/movies.rda".
☐ Document your data (see <https://r-pkgs.org/data.html>).We can see use_data() added two fields in the DESCRIPTION and stored movies.rda in the data/ folder. After loading and installing sap, we can see movies is now part the package NAMESPACE.
If we run devtools::load_all(), any data in the data/ folder are not lazy-loaded at this stage. However, the data are directly available in our environment for testing during development.
Ctrl/Cmd + Shift + L
If we want data to be part of the lazyload DB, we need to install the package.
Ctrl/Cmd + Shift + B
When the package is installed, we’ll see the following outputs related to data processing:
** data
*** moving datasets to lazyload DB
** byte-compile and prepare package for lazy loadingmovies is now part of sap’s namespace:

sap::movies7.1.3 Installed package files
The lazyload DB is located in the installed version of the sap package. Installation begins by reading and parsing the DESCRIPTION file to extract metadata such as the package name, version, and dependencies (e.g., Depends, Imports, Suggests). After checking the dependencies (and downloading and installing any that are missing), our source package is extracted, and the files are organized into specific folders:
Meta/: information about datasets, help files, and general package metadata.R/: byte-compiled R code stored as.rdband.rdxfilesdata/: datasets serialized into a lazyload database (stored as.rdband.rdxfiles in theR/directory)help/: binary help fileshtml/: html and css files for help files
The installed folders and files can be viewed using the file path accessor function, system.file().3
system.file(..., package = "", mustWork = FALSE)Passing "." to the ... argument of system.file() will return the installed location of the root folder of package.
To view the path to the R/ folder in our installed package, we can use:
system.file("R", package = "sap")path/to/installed/pkg/library/R-4.4/sap/RIf we combine this with fs::dir_tree(), we can see the files contained in the R/ folder:
fs::dir_tree(system.file("R", package = "sap"))path/to/installed/pkg/library/R-4.4/sap/R
├── sap
├── sap.rdb
└── sap.rdxDuring installation, data in the data/ folder are converted to .rdb and .rdx file formats and moved to the binary database stored in the R/ folder.
fs::dir_tree(system.file("data", package = "sap"))path/to/installed/pkg/library/R-4.4/sap/data
├── Rdata.rdb
├── Rdata.rds
└── Rdata.rdxThe lazyload database stores data objects in serialized form for fast retrieval (i.e., data are loaded only when explicitly requested, optimizing memory usage). The diagram below illustrates the development workflow for adding data to an app-package:
%%{init: {'theme': 'neutral', 'themeVariables': { 'fontFamily': 'monospace', "fontSize":"13px"}}}%%
flowchart TD
subgraph DESC["<strong>DESCRIPTION</strong>"]
LazyData("Add <code>LazyData: true</code>")
end
subgraph Data["<strong>data/ folder</strong>"]
app_data[("<br><code>app_data.rda</code>")]
end
subgraph Global["<strong>Global Environment</strong>"]
load_data[("<br><code>app_data</code>")]
end
subgraph Lazy["<strong>lazyload DB</strong>"]
app_data_lazy[("<br>Serialized<br> (<code>.rdb</code>/<code>.rds</code>/<code>.rdx</code>)")]
end
load("<code>devtools::load_all()</code>")
inst("<code>devtools::install()</code>")
DESC -->|"<code>usethis::use_data(app_data)</code>"|Data
Data --> load & inst
load --> |"Direct access for testing"|Global
inst --> |"Loaded only when<br>explicitly requested"|Lazy
7.2 data-raw/
The data-raw folder is not an official directory in the standard R package structure, but it’s a common location for any data processing or cleaning scripts, and the raw data file for datasets stored in data/.4
We’ll move the movies.RData file into data-raw/.
├── data
│ └── movies.rda
└── data-raw
└── movies.RDataWe can create a script to document sap::movies using usethis::use_data_raw("movies"):
✔ Adding "^data-raw$" to .Rbuildignore.
✔ Writing data-raw/movies.R.
☐ Modify data-raw/movies.R.
☐ Finish writing the data preparation script in data-raw/movies.R.
☐ Use `usethis::use_data()` to add prepared data to package.In the data-raw/movies.R file, we find the following:
## code to prepare `movies` dataset goes here
usethis::use_data(movies, overwrite = TRUE)We’ll adapt the script for the movies.RData file.
## code to prepare `movies` dataset goes here
load("data-raw/movies.RData")
usethis::use_data(movies, overwrite = TRUE)7.2.1 A data-raw/ example
If we look at the data in the dplyr package, we can see the data-raw/ folder contains a combination of .R and .csv files:
data-raw/
├── band_members.R
├── starwars.R
├── starwars.csv
└── storms.R
1 directory, 4 filesIn this example, the starwars.R script downloads & prepares starwars, then saves a .csv copy of the data in data-raw.
7.3 Documenting data
Documenting data can be tedious, but it’s worth the effort if you’ll be sharing your package with collaborators. There are multiple ways to store dataset documentation, but we’ll cover using a R/data.R file.5
In R/data.R, provide a title, description, a @details tag for more information:
#' IMDB movies data
#'
#' Movie review data from the Building Web Applications with Shiny
#' [course](https://rstudio-education.github.io/shiny-course/).
#'
#' @details
#' Read more about acquiring these data in the 'Web Scraping and programming'
#' section of [Data science in a box](https://datasciencebox.org/02-exploring-data#web-scraping-and-programming)
#' Below @details, include a @format tag with a one-sentence description of the data (and it’s dimensions).
#' IMDB movies data
#'
#' Movie review data from the Building Web Applications with Shiny
#' [course](https://rstudio-education.github.io/shiny-course/).
#'
#' @details
#' Read more about acquiring these data in the 'Web Scraping and programming'
#' section of [Data science in a box](https://datasciencebox.org/02-exploring-data#web-scraping-and-programming)
#'
#' @format A data frame with [] rows and [] variables:Each variable (column) in the data is documented with a combination of \describe and \item (pay close attention to the curly brackets):
#' \describe{
#' \item{variable}{description}
#' }After closing the curly brackets in \describe, place the name of the data in quotes ("movies") on the following line. Below is the documentation for the first five columns in the movies dataset:
#' IMDB movies data
#'
#' Movie review data from the Building Web Applications with Shiny
#' [course](https://rstudio-education.github.io/shiny-course/).
#'
#' @details
#' Read more about acquiring these data in the 'Web Scraping and programming'
#' section of [Data science in a box](https://datasciencebox.org/02-exploring-data#web-scraping-and-programming)
#'
#' @format A data frame with 651 rows and 34 variables:
#' \describe{
#' \item{title}{movie title}
#' \item{title_type}{type, fct (Documentary, Feature Film, TV Movie)}
#' \item{genre}{movie genre, fct (Action & Adventure, Animation, etc.}
#' \item{runtime}{movie length in minutes, num, avg = 106, sd = 19.4}
#' \item{mpaa_rating}{movie rating, fct (G, NC-17, PG, PG-13, R, Unrated)}
#' }
#'
"movies"If we load and document sap, we can see a preview of the help file:
Ctrl/Cmd + Shift + L
Ctrl/Cmd + Shift + D
We can view the documentation using the following in the Console:
?movies
movies datasetI’ve provided documentation for the full movies dataset below.
show/hide full movies data documenation
#' IMDB movies data
#'
#' Movie review data from the Building Web Applications with Shiny
#' [course](https://rstudio-education.github.io/shiny-course/).
#'
#' @details
#' Read more about acquiring these data in the 'Web Scraping and programming'
#' section of [Data science in a box](https://datasciencebox.org/02-exploring-data#web-scraping-and-programming)
#'
#' @format A data frame with 651 rows and 34 variables:
#' \describe{
#' \item{title}{movie title}
#' \item{title_type}{type, fct (Documentary, Feature Film, TV Movie)}
#' \item{genre}{movie genre, fct (Action & Adventure, Animation, etc.}
#' \item{runtime}{movie length in minutes, num, avg = 106, sd = 19.4}
#' \item{mpaa_rating}{movie rating, fct (G, NC-17, PG, PG-13, R, Unrated)}
#' \item{studio}{name of studio, chr}
#' \item{thtr_rel_date}{Theatre release date, POSIXct, min = 1970-05-19 21:00:00, max = 2014-12-24 21:00:00}
#' \item{thtr_rel_year}{Theatre release year, num, min = 1970, max = 2014}
#' \item{thtr_rel_month}{Theatre release month, num, min = 1, max =12}
#' \item{thtr_rel_day}{Theatre release day, num, min = 1, max =31}
#' \item{dvd_rel_date}{DVD release date, POSIXct, min = 1991-03-27 21:00:00, max = 2015-03-02 21:00:00}
#' \item{dvd_rel_year}{DVD release year, num, min = 1991, max = 2015}
#' \item{dvd_rel_month}{DVD release month, num, min = 1, max = 12}
#' \item{dvd_rel_day}{DVD release day, num, min = 1, max = 31}
#' \item{imdb_rating}{Internet movie database rating, avg = 6.49, sd = 1.08}
#' \item{imdb_num_votes}{Internet movie database votes, avg = 57533, sd = 112124}
#' \item{critics_rating}{Rotten tomatoes rating, fct (Certified Fresh, Fresh, Rotten)}
#' \item{critics_score}{Rotten tomatoes score, avg = 57.7, sd = 28.4}
#' \item{audience_rating}{Audience rating, fct (Spilled, Upright)}
#' \item{audience_score}{Audience score, avg = 62.4, sd = 20.2}
#' \item{best_pic_nom}{Best picture nomination, fct (no, yes)}
#' \item{best_pic_win}{Best picture win, fct (no, yes)}
#' \item{best_actor_win}{Best actor win, fct (no, yes)}
#' \item{best_actress_win}{Best actress win, fct (no, yes)}
#' \item{best_dir_win}{Best director win, fct (no, yes)}
#' \item{top200_box}{Top 20 box-office, fct (no, yes)}
#' \item{director}{Name of director, chr}
#' \item{actor1}{Name of leading actor, chr}
#' \item{actor2}{Name of supporting actor, chr}
#' \item{actor3}{Name of #3 actor, chr}
#' \item{actor4}{Name of #4 actor, chr}
#' \item{actor5}{Name of #5 actor, chr}
#' \item{imdb_url}{IMDB URL}
#' \item{rt_url}{Rotten tomatoes URL}
#' }
#'
"movies"7.3.1 Documentation example
To illustrate other options for data documentation, we’ll use the dplyr package again. As we can see from the folder tree below, dplyr stores its data in the data/ folder:
data/
├── band_instruments.rda
├── band_instruments2.rda
├── band_members.rda
├── starwars.rda
└── storms.rdaThe documentation for the datasets in dplyr are stored in R/ using a data- prefix:
R/
├── data-bands.R
├── data-starwars.R
└── data-storms.RThe three band_ datasets have documented in a single file, data-bands.R:
show/hide documentation for dplyr::band_ datasets
# from the dplyr github repo:
# https://github.com/tidyverse/dplyr/blob/main/R/data-bands.R
#
#' Band membership
#'
#' These data sets describe band members of the Beatles and Rolling Stones. They
#' are toy data sets that can be displayed in their entirety on a slide (e.g. to
#' demonstrate a join).
#'
#' `band_instruments` and `band_instruments2` contain the same data but use
#' different column names for the first column of the data set.
#' `band_instruments` uses `name`, which matches the name of the key column of
#' `band_members`; `band_instruments2` uses `artist`, which does not.
#'
#' @format Each is a tibble with two variables and three observations
#' @examples
#' band_members
#' band_instruments
#' band_instruments2
"band_members"
#' @rdname band_members
#' @format NULL
"band_instruments"
#' @rdname band_members
#' @format NULL
"band_instruments2"In the example above, note that two of the datasets (band_instruments and band_instruments2) have the @format set to NULL, and define the help search name with @rdname. The @examples tag can be used to view the dataset when users click ‘Run Examples.’
Either method works–what’s important is that each dataset in your package has documentation.
7.4 External data
The inst/extdata folder is used for external datasets in other file formats (.csv, .tsv, .txt, .xlsx, etc).6 These data files aren’t directly loadable using the package::data syntax or data() like with the data/ directory, but we can access them using system.file().
7.4.1 inst/extdata/
We’ll create the inst/extdata/ folder and save a copy of movies in the .fst file format:
library(fs)
library(tibble)
library(fst)fst package v0.9.8fs::dir_create("inst/extdata/")
fst::write_fst(
x = movies,
path = "inst/extdata/movies.fst",
compress = 75)fstcore package v0.9.14
(OpenMP was not detected, using single threaded mode)Then load, document, and install sap:
Ctrl/Cmd + Shift + L
Ctrl/Cmd + Shift + D
Ctrl/Cmd + Shift + B
We can import movies.fst using system.file() to create a path to the file:
tibble::as_tibble(
fst::read_fst(path =
system.file("extdata/", "movies.fst", package = "sap")
)
)fstcore package v0.9.18
(OpenMP was not detected, using single threaded mode)
# A tibble: 651 × 34
title title_type genre runtime mpaa_rating studio
<chr> <fct> <fct> <dbl> <fct> <fct>
1 Filly Brown Feature F… Drama 80 R Indom…
2 The Dish Feature F… Drama 101 PG-13 Warne…
3 Waiting for Guffman Feature F… Come… 84 R Sony …
4 The Age of Innocence Feature F… Drama 139 PG Colum…
5 Malevolence Feature F… Horr… 90 R Ancho…
6 Old Partner Documenta… Docu… 78 Unrated Shcal…
7 Lady Jane Feature F… Drama 142 PG-13 Param…
8 Mad Dog Time Feature F… Drama 93 R MGM/U…
9 Beauty Is Embarrassing Documenta… Docu… 88 Unrated Indep…
10 The Snowtown Murders Feature F… Drama 119 Unrated IFC F…
# ℹ 641 more rows
# ℹ 28 more variables: thtr_rel_date <dttm>, thtr_rel_year <dbl>,
# thtr_rel_month <dbl>, thtr_rel_day <dbl>, dvd_rel_date <dttm>,
# dvd_rel_year <dbl>, dvd_rel_month <dbl>, dvd_rel_day <dbl>,
# imdb_rating <dbl>, imdb_num_votes <int>, critics_rating <fct>,
# critics_score <dbl>, audience_rating <fct>,
# audience_score <dbl>, best_pic_nom <fct>, best_pic_win <fct>, …
# ℹ Use `print(n = ...)` to see more rowsWe’ll cover inst/ and system.file() in more detail in the next chapter.

7.5 Using movies
After documenting the movies data in R/data.R, we’ll remove the call to load() in the mod_scatter_display_server() function and replace it with a direct call to the dataset:
#' Plot Display Module - Server
#'
#' Handles the server-side logic for rendering a scatter plot.
#'
#' @param id *(character)* Namespace ID for the module.
#' @param var_inputs *(reactive)* A reactive expression containing
#' user-selected variables and attributes.
#'
#' @return No direct return value. This function generates a plot output.
#'
#' @section Details:
#' `mod_scatter_display_server()`:
#' - Uses `var_inputs` to dynamically generate a scatter plot with
#' user-selected variables.
#' - Reads from the `sap::movies` dataset
#' - Processes plot titles and axis labels to improve readability.
#'
#' @section Reactive Inputs:
#' - `var_inputs()$x`: X-axis variable.
#' - `var_inputs()$y`: Y-axis variable.
#' - `var_inputs()$z`: Color aesthetic variable.
#' - `var_inputs()$alpha`: Transparency level.
#' - `var_inputs()$size`: Size of points.
#' - `var_inputs()$plot_title`: Title of the plot.
#'
#' @seealso
#' - [`mod_var_input_server()`] for variable selection.
#' - [`scatter_plot()`] for generating the scatter plot.
#'
#' @family **Plot Display Module**
#'
#' @examples
#' if (interactive()) {
#' shiny::shinyApp(
#' ui = shiny::fluidPage(
#' mod_var_input_ui("vars"),
#' mod_scatter_display_ui("plot")
#' ),
#' server = function(input, output, session) {
#' selected_vars <- mod_var_input_server("vars")
#' mod_scatter_display_server("plot", selected_vars)
#' }
#' )
#' }
#'
mod_scatter_display_server <- function(id, var_inputs) {
shiny::moduleServer(id, function(input, output, session) {
inputs <- shiny::reactive({
plot_title <- tools::toTitleCase(var_inputs()$plot_title)
list(
x = var_inputs()$x,
y = var_inputs()$y,
z = var_inputs()$z,
alpha = var_inputs()$alpha,
size = var_inputs()$size,
plot_title = plot_title
)
})
output$scatterplot <- shiny::renderPlot({
plot <- scatter_plot(
df = movies,
x_var = inputs()$x,
y_var = inputs()$y,
col_var = inputs()$z,
alpha_var = inputs()$alpha,
size_var = inputs()$size
)
plot +
ggplot2::labs(
title = inputs()$plot_title,
x = stringr::str_replace_all(tools::toTitleCase(inputs()$x), "_", " "),
y = stringr::str_replace_all(tools::toTitleCase(inputs()$y), "_", " ")
) +
ggplot2::theme_minimal() +
ggplot2::theme(legend.position = "bottom")
})
})
}- 1
-
Updated
roxygen2documentation
- 2
-
The
moviesdata from our package namespace
After loading, documenting, and installing the package, we see the following application:
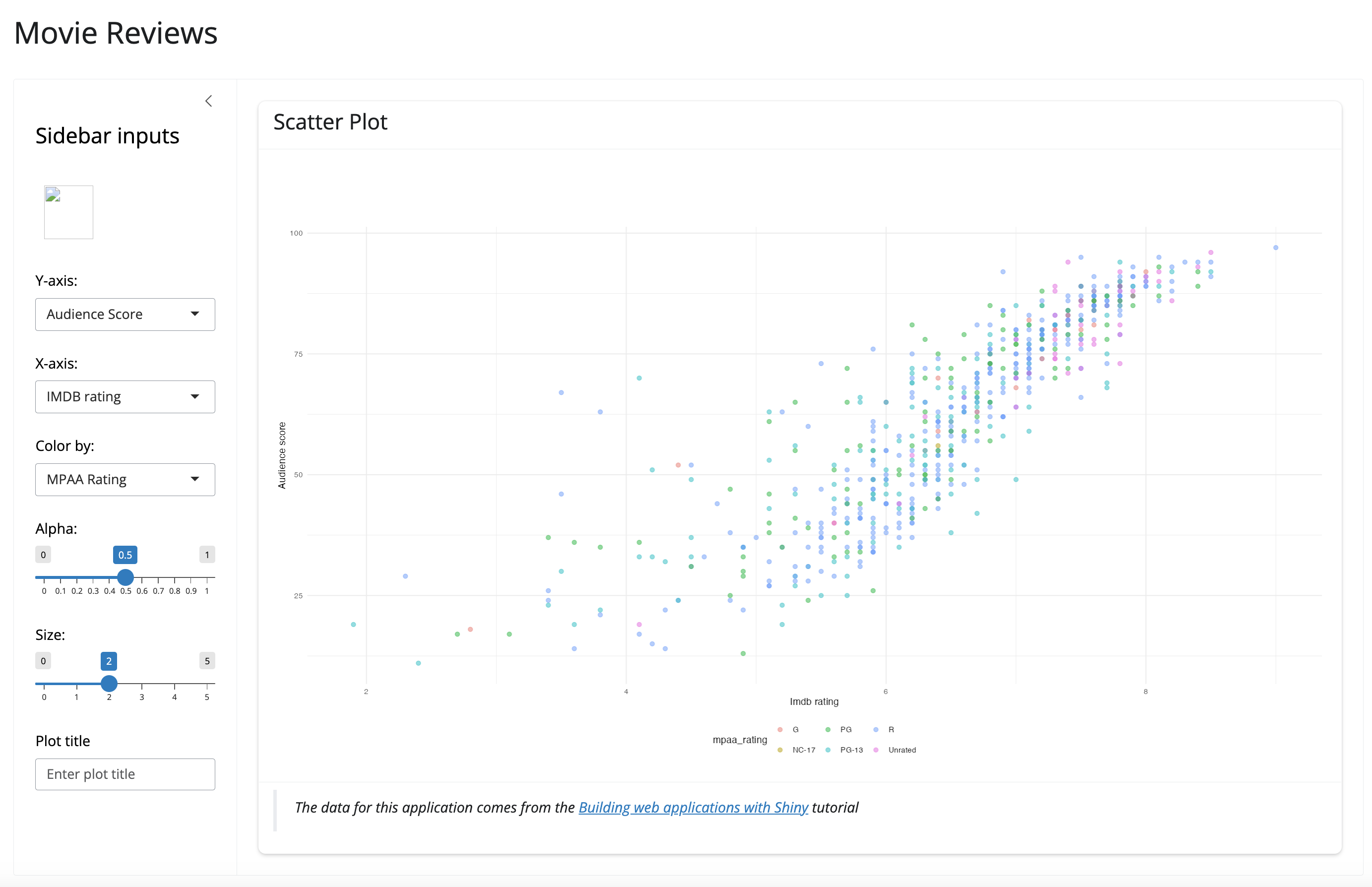
launch_app() with movies data fileRecap
It’s hard to imaging a Shiny app without any data, so knowing how and where to store and access data files in an app-package will make it easier to load and be reproducible in other environments. Here are a few other things to consider when including data in your app-package:
Read more about the data folder in the ‘Data in packages’ section of Writing R Extenstions and the ‘Data’ chapter of R Packages, 2ed.↩︎
For information on how to store and retrieve inside your application, see the chapter on app Data.↩︎
This is similar to
find.package("sap). Read more aboutsystem.file()andfind.package().↩︎Read more about the
data-rawfolder in R Packages, 2ed↩︎The
ggplot2package has a great example of documenting datasets in the R/data.R file↩︎Read more about the
inst/extdata/folder in R Packages, 2ed↩︎