show/hide
# drop missing values
penguins <- tidyr::drop_na(penguins)
ggplot(data = penguins)
ggplot2 syntax“making infinite use of finite means” - Wilhelm von Humboldt
Grammar is often defined as the system of rules for any given language and includes word meanings, internal structures, and word arrangement. Syntax is the form, structure and order for constructing statements. ggplot2‘s syntax is built on the grammar & syntax of R. In R, objects are like nouns, and functions are like verbs (i.e., functions ’do things’ to objects).
The ggplot2 syntax is comprised of layers, which we can use as templates to build increasing customize and complex graphs.
The data layer consists of a rectangular object (like a spreadsheet) with columns and rows:
# drop missing values
penguins <- tidyr::drop_na(penguins)
ggplot(data = penguins)
The mapping layer assigns columns (variables) from the data to a visual property (i.e. graph ’aes’ thetic)
ggplot(data = penguins,
mapping =
aes(
x = flipper_length_mm, y = bill_length_mm
)
)
Basic Template: Data, aesthetic mappings, geom
ggplot(data = <DATA>) +
geom_*(mapping = aes(<AESTHETIC MAPPINGS>))geom_*() functions include statistical transformations, shapes, and position adjustments for how to ‘draw’ the data on the graph
ggplot(data = penguins,
mapping = aes(
x = flipper_length_mm, y = bill_length_mm
)
) +
geom_point(
aes(
shape = species, color = sex
)
)
We can have multiple layers (data, mappings, geoms) in a single graph.
ggplot(data = penguins,
# layer 1
mapping = aes(
x = flipper_length_mm, y = bill_length_mm
)
) +
geom_point(
aes(
shape = species, color = sex
)
) +
# layer 2
geom_smooth(
mapping = aes(
x = flipper_length_mm, y = bill_length_mm),
se = FALSE
)
ggplot(data = <DATA>) +
geom_*(mapping = aes(<AESTHETIC MAPPINGS>)) +
geom_*(mapping = aes(<AESTHETIC MAPPINGS>))With a finite number of objects & functions, we can combine ggplot2’s grammar and syntax to create an infinite number of graphs!
ggplot(data = penguins,
# layer 1
mapping = aes(
x = flipper_length_mm, y = bill_length_mm
)
) +
geom_point(
aes(
shape = species, color = sex
)
) +
# layer 2
geom_smooth(
mapping = aes(
x = flipper_length_mm, y = bill_length_mm),
se = FALSE
) +
# layer 3
facet_wrap(
. ~ island, ncol = 2
) +
# labels
labs(
x = 'Flipper length (mm)', y = 'Bill length (mm)',
title = 'Penguins', subtitle = 'Bills vs. Flippers'
) +
# themes
theme(legend.position = "top") 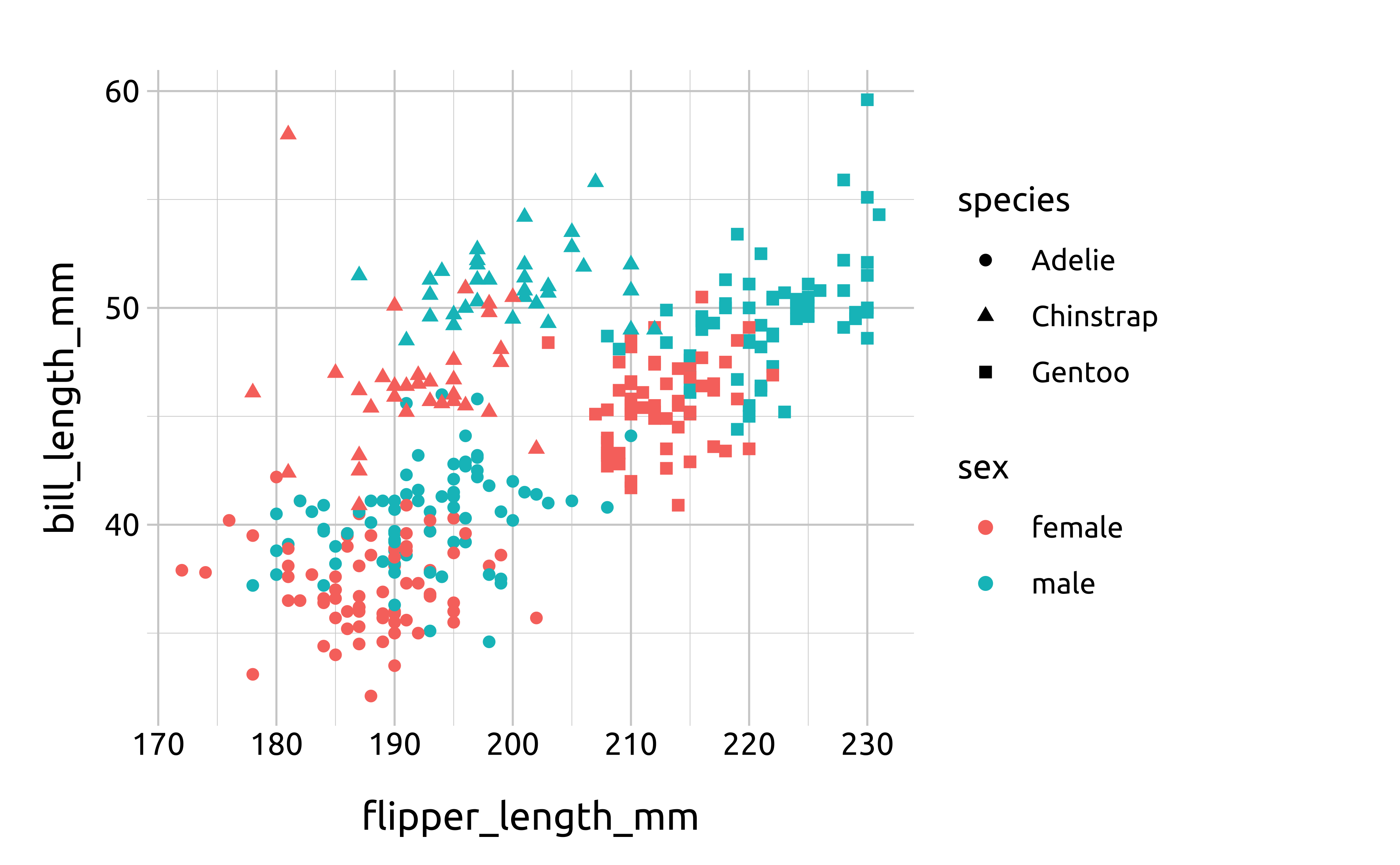
Template + 2 Layers + Facets + Theme + Labels
Layers = infinitely extensible!
ggplot(data = <DATA>) +
geom_*(mapping = aes(<AESTHETIC MAPPINGS>)) +
geom_*(mapping = aes(<AESTHETIC MAPPINGS>)) +
facet_* +
theme() +
labs()Graphs have been categorized into the following types (you can see them in the floating table of contents to your left).
Univariate: if you have a single column you’re trying to visualize
Amounts: counts or simple summary statistics of one or two columns in a dataset
Proportions: ratio displays of part-to-whole
Distributions: displaying the shape of a variable’s values (normalcy, skewness, kurtosis, etc.)
Dates & Times: changes in quantitative or categorical variables over a dimension of time (date-time, date, year, month, quarter, etc.).
Relationships: how does the change of values in variable x affect the values in variable y (and possibly z)?
Some graphs can justifiably belong to more than one category, and wherever this is the case, I’ve tried to include links to other applications in the notes.
I’ve made an effort to write the graph code so it can be read and understood without having to execute it.1 However, the examples assume the reader has already answered the question, “what kind of data do I have?”2
Each graph has the following sections:
Prerequisites
Description
Set up
The grammar
labs_ prefixggp2_ prefixMore info
I’ve attempted to balance brevity and clarity, but with the assumption that its best to err on the latter. I’ve also followed the general principle that if a graph can be easily built using one of ggplot2 ’s geom_* functions, that method is shown first.
This field manual follows a Rule of Least Power Principle, in the sense that “a language with a straightforward syntax may be easier to analyze than an otherwise equivalent one with more complex structure.”↩︎
If not, I highly recommend the skimr and inspectdf packages for getting to know your data better.↩︎